
そこ曲がったら、量子坂?(上り)
【材料・創薬・医療】
Ⅰ 実装容易な断熱ショートカット・インスパイアード・プロトコルを用いて、タンパク質折り畳み問題を、効率的に解いた主張する論文
Ⅵ 量子版トランスフォーマーが古典版よりも優れていることを示した、と主張する論文 追加あり
Ⅷ 低分子医薬品候補物質の発見において、量子古典ハイブリッド敵対的生成ネットワークが、より優れていると主張する論文
XⅦ 材料シミュレーションに必要な量子リソースを大幅に削減できた、主張する論文
XIX 量子古典ハイブリッド生成モデルは、古典生成モデルより、高質なヒット化合物を探索できると主張する論文
XX mRNA二次構造予測問題で、変分量子アルゴリズムに量子加速性があるかを検証した論文
【暗号・通信】
Ⅱ RSA2048をNISQマシンで効率的に解読できると主張する論文
XⅣ 小規模な既存暗号は、従来の想定よりも脆弱、と解釈できる論文
【物理・量子化学】
Ⅲ テンソルネットワークが乱流解析でも有効と主張する論文
Ⅺ FTQCでのみ実行可と考えられていた量子アルゴリズムをNISQで実行したという論文
XⅧ 量子SVMは古典SVMと比べて境界層の剥離を正確に検出できる、と主張する論文 追加あり
【金融】
Ⅳ 量子インスパイヤード・アルゴリズムは、堕天使予測にかかる時間を短縮できる、と主張する論文
Ⅴ 量子インスパイヤード・アルゴリズムが、演算の高速化とパラメータ数削減を達成した、と主張する論文
Ⅶ 量子強化学習によるディープ・ヘッジングが、デルタヘッジよりも優れている、と主張する論文
XV 量子カーネル法の精度を向上させたと主張する論文
【その他】
Ⅸ 飛行経路最適化問題では、サイズが小さい領域で、量子アルゴリズムが古典アルゴリズムより速いと主張する論文
Ⅹ ブラックボックス関数最適化問題において、データにノイズが多い場合、量子ニューラルネットワークは古典ニューラルネットワークより精度が高い、と主張する論文
Ⅻ 経路探索で量子古典ハイブリッドNNが古典NNより優れていると主張する論文
XⅢ 「不毛な台地」を回避したと主張する論文
XⅥ 変分量子アルゴリズムに量子優位性は、「ほぼない」と予想する論文
【Appendix】
Appendix 1 量子十二学坊! Quantum for Bio
Appendix 2 NISQで、マグネシウムの腐食をシミュレートする
Appendix 3 NISQの限界を実証したと解釈できる論文
Appendix 4 忠実度1の量子回路は、確率的に探索可能と主張する論文
Appendix 5 最初の量子優位性は、物性シミュレーションで観測されると予測した論文
Appendix 6 テンソルネットワークを使ってLLMを、上手く圧縮した主張する論文
【1】論文の主張
バスク大学(スペイン)、Kipu Quantum(※)、上海大学、バスク科学財団(Ikerbasque)の研究者は、新しい断熱量子計算プロトコルで優れた結果を出したという論文をarXivにて公開した(2022年12月27日付け)[*1]。以下、[*1]を本論文という。
新しい断熱量子計算である「断熱ショートカット」に触発された、新しいプロトコル(デジタル化CDプロトコル、DCDプロトコル)を、タンパク質折り畳み(フォールディング)問題に適用した。DCDプロトコルは、パラメータ付き量子回路(ansatz)と古典コンピュータを使う量子古典ハイブリッド・プロトコル。基底状態のエネルギーへの収束性等を判断指標として、QAOA(近似的量子最適化アルゴリズム)と比較したところ、DCDプロトコルが勝った。
余談ながら、論文名にある”CounterDiabatic(CD)”に、正式な和訳はないようであるが『非断熱遷移に抗って、断熱遷移を堅持する』という意味合いで、非断熱対抗と訳せなくもない。
※ドイツの量子ソフトウェア・スタートアップ。こちらのⅡ個別整理【2】EUを参照。
【2】学術的な整理
(1) タンパク質折り畳み問題
アミノ酸情報(のみ)から、タンパク質の立体構造を予測することを、タンパク質折り畳み問題という。生理的条件下で、多くの立体構造から唯一つを選択するカラクリは、自由エネルギー最小の状態を選択するからである、と理解されている。
この問題は計算負荷が大きい。従来のアプローチは、分子動力学法をスパコンで実行するというものであり、マシンパワー頼みであった。この従来アプローチよりも計算速度を上げる試みが、2種類ある。一つは、深層学習で計算速度を加速させる努力であり、2020年12月(Google傘下の)ディープマインドによるアルファ・フォールドという形で結実した[*13](メタも後追いした)。NVIDIAもAIでタンパク質をデザインしたと発表した[*14]。
別の試みは、量子計算である。タンパク質は、自由エネルギー最小の状態を選択して(立体構造を形成して)いるのだから、タンパク質折り畳み問題は、最適化問題に帰着できる。そこで、(組み合わせ)最適化問題に特化している、現時点で使用可能な量子コンピュータ、量子アニーラを使おうという試みである。量子アニーラが使用しているアルゴリズム「量子アニーリング」は、断熱量子計算の一種である。ここで、ようやく断熱ショートカットを説明する下地が、整った。
(2) 断熱ショートカット
本論文を読むための、断熱ショートカットに関する知識は、[*2]を参照した。なお、本論文の著者たちは、断熱ショートカットの第一人者のようである。
断熱量子計算・量子アニーリングは、ハミルトニアンの基底状態をたどることによって最適化問題の答えを得る計算手法である。系に対して、十分にゆっくりとした操作を行えば、断熱量子計算が可能なのであった。しかし、計算速度を上げるという試みなのに、ゆっくりした操作で良いのだろうか。素早い操作で、つまり短い時間で、断熱量子計算はできないのだろうか?
「実はできる」というのが、断熱ショートカットというアイデアである。時間を短縮するから、ショートカットという刺激的な言葉が使われている。具体的には、対象とする量子系の断熱時間発展を記述するハミルトニアンとは異なるハミルトニアンを用いて、時間発展を記述する。その方法は2つに大別される:①制御項を加える方法、②動的不変量を用いる方法、である。本論文では、①を用いているので、以下①断熱時間発展ハミルトニアンに、制御項と呼ばれるハミルトニアンを加える、について記述する。
(3) 制御項の導入
系に働く、一種の「慣性力」を打ち消すような力を加えることができれば、たとえ素早く操作をしたとしても、断熱量子計算ができる。そのような力に相当するのが、counterdiabatic項(日本語では、制御項)と呼ばれるハミルトニアンである。制御項は、元のハミルトニアンの固有状態が分かれば、構成することができる。ただし、固有状態を見つけることは、一般に難しい。さらに、見つけたとしても、それを実現(物理実装)することは、一般に難しい。
そこで、次のような、実装可能な制御項を構成する方法が提案されている。
❶ ユニタリー変換を用いてハミルトニアンの異なる表現を得る。
❷ 状態に依存した制御項を用いる。
❸ 近似的な制御項を構成する:㊀制御項を何らかのパラメータで展開して、低次の項のみを用いる方法や、㊁元のハミルトニアンを近似的に簡略化してそれに対する制御項を構成する方法、などがある。
本論文では、❸㊀を採用しているので、以下❸㊀について記述する。❸㊀で汎用的なものは、変分原理に基づいて、パラメータを求める方法である。具体的に言うと、制御項と元のハミルトニアンが満たす交換関係を利用する。制御項を近似制御項で代替すると、交換関係=0とならない。そのため、近似誤差が生じる。この近似誤差を最小化する条件を課すことで、近似制御項のパラメータを求めることができる。ただし、こうして求められる近似制御項は、ユニークでない場合もあるようで、その場合は、補助的な条件を適宜用いる必要がある。
制御項を近似した場合、大域的最適解への収束が保証されないことは、言うまでもないであろう。
なお、本論文によると「最適な制御項の選択は、強化学習やモンテカルロ木探索などの機械学習手法によって取り組まれることがある」。
【3】本論文の成果
ここで、断熱ショートカットを整理すると、次のようになるだろう:①断熱量子計算を加速するには、断熱時間発展ハミルトニアンに制御項を加えた、新しいハミルトニアンを(改めて)時間発展生成子として使えば良い。②制御項は、変分法を使えば、近似制御項として得ることができる。
(1) 本論文の本質的なアイデア
本論文では、次のように考えた(と理解している)。非断熱遷移が支配的である場合、制御項が支配的な役割を果たしているはずである。従って、その場合、制御項のみによる時間発展を考慮すれば良いはずである。非断熱遷移が支配的であるケースにおいて、近似ではない制御項を導出することは、(固有状態を求めることが難しいから)難しい。しかし、近似制御項なら導出可能ではないか。つまり、非断熱遷移が支配的であるケースでも、近似制御項のパラメータを調整することで、(近似)制御項のみによる時間発展を考慮することが出来るのではないか? 近似制御項のパラメータは、古典コンピュータの強力な最適化アルゴリズムを使えば、何とかなるのではないか。
というわけで、(近似)制御項による時間発展のみ量子コンピュータ(もちろんNISQマシン)に担わせ、あとは一切合切を古典コンピュータに任せる、というプロトコル(以下、DCDプロトコル)が考案された。こうすることで、物理実装も軽くなる、とする。
なお、本論文における近似制御項の構成法はヒューリスティックスである。従って、DCDプロトコルにおける近似制御項を、数学的に系統立てて見つけられるわけではない。
(2) シミュレーションの内容
本論文では、アミノ酸数の異なる様々なタンパク質へDCDプロトコルを適用している。アミロイドβペプチド(KLVFFA)[*3]は6量子ビット系に、神経ペプチドαバッグセル(APRLRFY)は9量子ビット系に、環状ペプチド阻害剤(AVDINNNA)は13量子ビット系に、オキシトシン(CYIQNCPLG)は17量子ビット系で実行している。
QAOAをベンチマークとして性能比較では、対象タンパク質が環状ペプチド阻害剤(AVDINNNA)である。反復回数は100回、(QAOAとの比較では)最適化はAdamを使用。勾配は(量子回路パラメータの勾配計算なので)パラメータシフト法を用いている。
比較指標として、①20インスタンスの平均エネルギー、②平均エネルギーの分散、③最良インスタンスにおけるエネルギーを用いている。結果は、QAOAは基底状態のエネルギーを導出できなかったので、③はDCDプロトコルの圧勝。①も当然、DCDプロトコル。②もDCDが勝っている。DCDが導出する最適解(最小エネルギー)は、反復回数30回あたりで、基底状態のエネルギーに張り付いているから、分散も小さい。なお、パラメータ・スケーリングはO(N2)である。
また、ハードウェア効率型の量子回路と比較しているし、イオンQ・IBM・Googleそれぞれのハードウェアに実装し、量子回路の最適化戦略を考察している(が割愛)。
【4】課題と考察
以下のような課題と考察があげられている。
(1) 収束性
N = 17量子ビットのような大きなシステムサイズでは、古典的な最適化アルゴリズム(Adam及びAdaGradを使用)や低い反復ステップのためか、100回の反復では、定常値に収束することが難しい。これは、システム規模が大きくなると解空間が急激に増大し、大域的な解を求めることが困難になるためである。システムサイズが大きい場合に、高い成功確率で効率的に基底状態に到達するためには、全体最適化が必要になるかもしれない。
(2) ノイズ
ノイズがある場合でも、DCDプロトコルは、かなりうまく機能する。とはいえ、最終的な収束エネルギーは基底状態のエネルギーと比較してかなり持ち上がっている。最後に到達した時点では、まだ揺らぎがある。ただし、シミュレーションは、「量子誤り緩和」を使わずに実行された。
【5】まとめ
(1) 古典的最適化アルゴリズムでパラメータを調整することにより、近似制御項のみで断熱時間発展を記述できるのではないか、というアイデアを試して良い結果を得た。まとめると、そういうことであろう。
(2) ただ、本論文の著者たちは、アブストラクトで「アミノ酸配列の最低エネルギー配置を求めることは、NP困難である。私たちが提案する計算プロトコルは、最新の量子アルゴリズムを凌駕する性能を実現した」という旨の記述をしている。これは、やや誤解を招く表現ではないかと思う。量子コンピュータ(NISQマシン)でNP困難問題を効率的に解けるのか(NP困難問題が効率的に解けるのなら、NISTが推す耐量子暗号である格子暗号も、安全ではなくなる!)?と驚いたが、そうではなかった。
(3) やはり、まずサイズの問題がある。次に、計算プロトコルの要である近似制御項を数学的に作り出す方法が、確立されていない。それらが解決しない限りは、格子暗号への脅威とはならないと思われる。しかし断熱ショートカットは新しい研究分野であり、今後大きく発展する可能性を秘めている。少なくとも、注目すべき技術であることは、間違いないだろう。
【1】論文の主張
2022年末(12月23日)に、中国の研究者たちがarXivに投稿した論文[*4](以下、本論文)は、衝撃的な内容を含んでいた。現在主流の公開鍵暗号RSA2048が、現存する量子コンピュータ(NISQマシン)で解読できると推定していたからである。しかも、その解読法は、最近ベクトル問題を解くというアプローチであった。耐量子暗号の主流である格子暗号は、最近ベクトル問題が効率的に解けてしまえば、解読されてしまう。耐量子暗号さえ、NISQで解読できる主張しているのだろうか?
暗号学者ブルース・シュナイアーは、自身のブログ[*5]で、本論文について注意を喚起した(23年1月3日)。それに対して、(説明不要なほど著名な)スコット・アーロンソンは、自身のブログ[*6]に『私が25年間に見た中で最も積極的に誤解を招く』と書き、疑わしいとの判断を示した(23年1月4日)。
【2】学術的な整理
(1) 解法の構成
本論文では、シュノアのアルゴリズムにおけるsrペア問題が、最近ベクトル問題(CVP:Closest Vector Problem)に変換されている。CVPは、基底で張られる格子の中で、目標ベクトルに近いベクトル(格子点)を求める問題である。格子暗号はCVPを見つける困難さに基づいている。本論文は、このCVPを解くことで、「素因数分解問題の困難性に基づいている」RSA暗号を解く、という構成になっている。
CVPはNP困難な問題であり、多項式時間で、厳密に解くことは難しい。ただし近似解は多項式時間で得ることができる(と数学的に証明されている)。その方法として主に、❶格子基底簡約、❷格子点サンプリング(Enumeration)、❸格子篩(Sieving)、が知られている。❶には、LLL(Lenstra-Lenstra-Lovasz)法や、Babaiの最近平面アルゴリズムがある。本論文は、Babaiのアルゴリズムを使っている。
(2)Babaiのアルゴリズム[*7]
CVPは、基底で張られる格子の中で、目標ベクトルに近いベクトルを求める問題であった。実は、同じ格子を張る別の基底は、無限に存在する。つまり、基底を変えても格子は変わらないという性質がある。この性質を使って、都合の良い基底を選び、その基底で張られる格子の中で最近ベクトルを求めるという問題に、CVPを置き換えることができる。この基底の変換を「簡約」と呼ぶ(英語ではreducedであり、縮小とも言う)。簡約は、線形代数(≒行列計算)で広く知られているグラム・シュミット直交化法を使って、実行できる。簡約基底の一つがLLL簡約基底である(本論文では、パラメータδを使ったLLL簡約基底を使っている)。
Babaiのアルゴリズムでは、グラム・シュミット係数を”丸めた”係数とLLL簡約基底の線形結合で、CVPの近似解(近似ベクトル)を表現する。グラム・シュミット係数は、 LLL簡約基底とグラムシュミット直交基底の内積から計算される。グラム・シュミット係数を丸めるとは、(元の空間の)直交補空間におけるベクトル自乗長さが短くなるように、グラム・シュミット係数に最も近い整数を選んでいく作業(Babaiリフティング)である。
【3】本論文の成果
(1)本論文のアイデア
本論文のアイデアは、Babaiのアルゴリズムで求めたCVPの近似解の精度をQAOA(近似的量子最適化アルゴリズム)を使って高めるというものである。精度は低いが、高速なBabaiアルゴリズムを採用し、低い精度はQAOAでカバーする戦略と考えられるだろう。
本論文では『丸め作業(Babaiリフティング)において、2つの丸め関数の値を同時に計算に取り込むことができれば、より質の高い解を得ることができる』と述べている。そして『しかし、その処理は、古典的な演算量を指数関数的に増加させるので、古典的な計算機では手が出せない。そこで、量子ビットの重ね合わせ効果を利用して、2つの丸め関数で得られた係数値を同時に符号化する』ことを提案している。
最適化問題の古典的な定式化は、シンプルである。Babaiリフティング で得られた係数に、余計なスカラーxi∈{0,±1}を加え、目標ベクトルとのL2ノルムで、損失関数を構成する。量子化は、先の余計なスカラーxiを、パウリZ基底にマッピングされた量子演算子と置換することで行う。QAOAでパラメータを更新することにより、ハミルトン系の近似的な基底状態を見つけることができる。
本論文によれば『この定式化で、必要な量子ビットの数は、格子の次元に等しい。格子の次元nは、n~2c×logN/loglogNを満たし、c≒1。 従って,mビットの整数Nを因数分解するために必要な量子ビットの数はO(m/logm)となる』。
(2)セットアップ
ハードウェアは、周波数調整可能なトランズモンで構成される10個の量子ビットと9個のカプラを、鎖状に配置した超伝導量子プロセッサーである。このハードウェアを用いて、3つの整数(11ビット整数1961、26ビット整数48567227、48ビット整数261980999226229)の因数分解を行うことによってアイデアの検証を行う。なお、単一量子ビットの回転とCZゲートについて、それぞれ99.9%と99.5%に近い平均忠実度が得られている、という。
また、SWAPネットワークの偶数層と奇数層に、ZZ-SWAPブロックのアップダウンを組み合わせた結果、アダマール・ゲートの深度を低減することができたようである。
(3)成果
本論文の成果は『RSA2048の解読に、372個の物理量子ビットを持つ量子回路と数千の深さが必要であることがわかった』という主張に尽きる。RSAを高速に解読できることが、数学的に証明されているショアのアルゴリズムを実装するには、量子ビット数2000万のFTQC(エラー耐性量子ゲート方式の量子コンピュータ)が必要と予想されていた[*8]。それが、372個と十分いう主張は衝撃である。
372の根拠は、先にあげた2c×log2N/log2(log2N)である(2m=N)。2048ビットだと、2∗2048/log22048≒372(372.3636・・・)となる。回路の深度については、3種類のトポロジーについて検討して、1000~1500程度の数値を得ている。具体的には、全結合系(Kn)、2次元格子系(2DSL)、1次元鎖系(LNN)について検証し、QAOAを1層で構成した場合の量子回路深さは、Knで1118、2DSLで1139、LNNで1490。
【4】まとめ
本論文で主張していることは、必要な量子ビット数が少なくて済むであろうということに過ぎない。著者たちも「QAOAの収束が曖昧なため、本アルゴリズムの量子高速化は不明確である」と述べているし、アーロンソンもそこを指摘している。つまり、RSA2048に対する脅威性は、それほどないと考えられる。格子暗号に対する脅威性も、同様である。ただ、QAOAは進化している。例えば、シンガポールのスタートアップEntropica Labsは、再帰的QAOAの適応版というAda-RQAOAなるアルゴリズムを、開発している。計算コストでQAOAを凌駕したと主張している[*9]。ゆえに、注意は必要だろう。もっとも、IBM Ospreyは433量子ビットを備えており、372を超えているのだから、検証作業を行うことで、論争自体に、決着はつくだろう。
補足1・・・natureのニュース(23年1月6日付け)[*10]には、中国の物理学者Chao-Yang Luが「QAOAアルゴリズムを実行するには、372個のキュービットのそれぞれが、99.9999%の精度で動作する必要があると述べた」との記述がある。
補足2・・・富士通は、量子シミュレータを使って、以下の結果を得たと発表した(23年1月23日)[*15]:RSA2048を解読するには、量子ビット=約1万、ゲート数=約2兆2,300億、量子回路の深さ=約1兆8,000億が必要。
【1】論文の主張
量子多体系において有効なシミュレーション手法を、(非圧縮性流体の)乱流解析に適用して良い結果を得た、という論文[*11](以下、本論文)が、arXivにて公開された(2022年7月)。英米、シンガポール、ドイツの研究者による共同研究(筆頭著者は、英国の研究者)である。ちなみに英国の構成は、オックスフォード大学、(米Quantinuumに買収された)ケンブリッジ・クォンタム・コンピューティング、バース大学。
ここで言う、量子多体系で有効なシミュレーション手法は、テンソルネットワーク形式を用いた計算手法である(以下、テンソルネットワーク法と呼ぶ)。”良い”とは、ラージ・エディ・シミュレーション(LES)と比較して、速度場を表すために必要な自由度(計算格子点の数)を1桁以上減らしても、同等以上の精度が得られた、という意味である。
【2】学術的な整理[*12]
(1) テンソルネットワーク法と固有直交分解(シュミット分解)
物理において、何度も発明されたと形容されるテンソルネットワーク法は、計算量の爆発を回避するため、「重要な自由度のみを残す(抽出する)」という発想を体現する。同じような発想は当然ながら、流体解析にもあり、固有直交分解(POD)という方法が用いられてきた。PODでは、与えられたデータを最も効率よく表現(展開)できるように、基底を求める。PODで得られる基底をPOD基底と呼ぶ。POD基底は、元の次元Nよりもずっと小さい次元r(r«N)の空間を張る。r«Nであるから、計算コストを抑えることができる。
(2) 固有直交分解(POD)基底の導出
POD基底は、①流れ場の物理量x(t)をr次元で表現、②射影演算子で①を元のN次元空間に戻した際に、|①ー②|が最小となるように決定する(ノルムは、通常L2ノルムを使う。本論文でもL2ノルム)。x(t)=∑係数×POD基底、で表現される。本論文では、計算格子は、粗い格子と細かい格子に分けられ、それぞれの格子でPOD基底を求める(従って、正確には、x(t)=∑係数×粗い格子のPOD基底×細かい格子のPOD基底)。
【3】本論文の成果
(1) 本論文のアイデア
本論文が、テンソルネットワーク法を乱流解析に適用できると考えた理由は、乱流エネルギー・カスケードのスケール・ローカリティ(ある長さスケールの渦が、同じスケールの他の渦と優位に相互作用するという性質)を是としたからである。従って、離れたスケール間の相関が重要である場合、テンソルネットワーク法は数値的に非効率である可能性がある。そこで最初に、スケール・ローカリティを検証している。2次元の時間発展ジェット(TDJ)と3次元のテイラーグリーン渦(TGV)のDNS解を対象に、スケール・ローカリティが明らかになったとする。
その上で、乱流解析にテンソルネットワーク法を適用している。テンソルネットワーク法は、局所的な相互作用を持つ量子系のシミュレーションにおいて、実現されていない長距離相関を取り除くことで、効率的なシミュレーションとなったからである。まず、1次元的な構造を持つテンソルネットワークである行列積状態(MPS)を使って1次元系の定式化を行っている。速度をMPSで表現することで、乱流解析にMPSを適用する、という枠組みである。それを2次元、3次元へと拡張している。
[補足]
時間発展は、支配方程式(ナヴィエ・ストークス方程式)を損失関数とした上で、損失関数を最小化する最適化問題を解く、という形で行う。これは、PINN(Physics-Informedニューラルネットワーク)の要領である。本論文では、L2正則化も行っている(連続の式を用いている)。最適化は、パラメータ付き量子回路(ansatz)で、勾配ベースのアルゴリズムを使って実行している。
(2) シミュレーション結果
2次元の時間発展ジェット(TDJ)と、3次元のテイラーグリーン渦(TGV)におけるアンサンブル平均したレイノルズ応力(テンソル)を比較対象としている。アンサンブル平均は、統計的に均質な流線方向に対して行う。DNS解を正解とした上で、テンソルネットワーク法による近似解とLESによる近似解を比較した。DNS解との差異は、TDJ及びTGVで、テンソルネットワーク法が小さい(精度が高い)。
なお、TDJのレイノルズ数は1000。TGVに至っては、800。乱流は発生しているだろうが、実応用を考えた場合(非圧縮性流体であっても)、レイノルズ数が1桁若しくは2桁は小さいだろう。
(3) 本論文の成果
本論文の成果は、テンソルネットワーク法とLESのシミュレーション結果よりも、自由度(計算格子点の数)が少なくて済むことである。(コルモゴロフ・スケールまでを対象とする)DNSの場合は、レイノルズ数Reに対して、Re9/4。テンソルネットワーク法の場合、Re4γlogRe。ここで、Reγ~χの関係を仮定している。χは、L2ノルムで計測して、99%の精度でDNS解を表すようなPOD基底の数(結合次元)である。γ<9/16であれば、Reに対する増加速度が遅くなるため、テンソルネットワーク法が(計算コスト的に)有利としている。
(2次元の)TDJの場合、Re=1000、χ=25なので、γ=0.466となる。この場合、LESの自由度/テンソルネットワーク法の自由度=2であり、テンソルネットワーク法が有利となる。本論文では、「十分に大きなReに対してもγ≈0を示唆している」と記述されている。続いて、「このReによるシュミット数の飽和(γ≈0の意味)は、TDJに特有の現象なのか、それとも2次元乱流の一般的な性質なのかを調べるのは興味深いことです」と書かれている。
一方、「(3次元の)TGVの場合、γ≒0.71で、3K/16より大きい(K=3)」とテンソルネットワーク法が不利であることを認めている。ただ、「しかし、高次元のテンソルを操作するための数値的方法は活発な研究分野であり、将来的にはMPSアルゴリズムのχに対するスケーリングを改善できる可能性があることを指摘する」と将来への期待を表明している。なお、Re=800、χ=207で計算すると、γ=0.798となる。
【4】まとめ
機械学習の言葉を使えば、「乱流エネルギー・カスケードのスケール・ローカリティ」というドメイン知識を使って、特徴量抽出したら良い結果が出た。そうなるだろう。しかし、以下に示すように、テンソルネットワーク法が乱流解析においてLESより優れているとは、言い難い。本論文のメッセージは、テンソルネットワーク法を乱流に適用することにより、量子コンピュータ(NISQマシン)で乱流解析を行う道筋がついた、ということだろうか。
【0】はじめに
仏クレディ・アグリコルCIBは、金融実務における量子コンピューティングを使用した概念実証が、決定的な結果をもたらしたと発表した(23年1月26日)[*16]。
クレディ・アグリコルCIBは、クレディ・アグリコル銀行の投資銀行部門であり、 仏Pasqal(中性原子方式のH/Wベンダー)及びスペインのMultiverse Computing(S/Wベンダー)と協業し、金融商品の評価並びに信用リスク評価に関する概念実証を2021 年 6 月に開始していた。
対象となった信用リスク評価を具体的に述べると、「債務者の信用格付けが、投資適格から非投資適格への格下げを予測すること」である。結果をまとめた論文[*17](以下、本論文)は、22年12月6日にarXivにて公開された。なお社債市場では、債務者の信用格付けが、投資適格から非投資適格になることを堕天使と呼ぶ(ので、以下でも、その慣例を踏襲する)。
【1】本論文の主張
(1)古典量子ハイブリッド・モデルと、(2)量子インスパイアード・モデルについて、結果を報告している。(1)は、古典モデル対比で、同程度の性能を少ない学習器で達成し、実行時間は約1/3になった。(2)は、少ない学習器でありながら、古典モデル対比で、(わずかに)高い性能を示し、実行時間は約1/9になった。
【2】セットアップ
(1) データセット
約150の特徴によって特徴付けられる9万以上のインスタンスで構成された、20年間(2001年~2020年)の公開データをデータセットとして使用している。
予測因子は「格付け、金融市場、株式市場の変数及び、そのトレンド」である。隔年ごと、四半期ごと、5年ごとに計算されている。対象企業は、70カ国に所在する10業種・2000社超に及ぶ。
トレーニングセットは、2001年~2016年までの約65,000例で構成。テストセットは、2016~2020年の約26,000の例で構成される。
(2) ベンチマークと計量指標
ベンチマークは、ランダムフォレストである。計量指標は、精度(precision)及び再現率(recall)である。精度は、分類器(分類タスクを行う学習器、識別器とも呼ばれる)が負のサンプルを正のサンプルと間違えない能力を言う。再現率は、モデルがすべての正のサンプルを見つける能力である。
ランダムフォレスト(決定木1,200本)は、再現率=83%、精度=28%を達成した。本論文の目標は、 再現率をR=80%以上に保ちながら、堕天使の予測精度を上げることである。
精度はビックリするほど低いが、これは、データが不均衡なためである。つまり、 本ケースでは、堕天使(のデータ)が非常に少ないためである。具体的には、トレーニングセットでは9%、テストセットでは12%が堕天使であった。そのようなデータセットを対象とした、機械学習タスクは精度が出にくい。データが不均衡な場合(は一般的に)、オーバーサンプリングという手法が採用される。そして、オーバーサンプリングを採用すると、精度は急激に向上する。
例えば、米ノースウェスタン大学の研究者がarXivに投稿(22年12月4日)した論文[*18](※)は、代表的なオーバーサンプリング手法である SMOTE (Synthetic Minority Oversampling Technique)を使って、精度が30%程度から90%程度まで上がることを、示している(学習モデルは、ロジスティック回帰、k近傍法、サポートベクターマシン、ニューラルネットワーク。ランダムフォレストは含まれていない)。ただ、オーバーサンプリングを使って精度を上げることは、積極的な過学習であるから、予測力を上げるという点において、ほぼ意味がない。
※ この論文の目標は、堕天使が倒産するか/投資適格に戻るか、を判別することである。従って、投資適格から非適格に堕ちる堕天使を予測する本論文とは、目標が異なる。
【3】本論文のモデル
2つのモデルを用いて、古典アルゴリズム(ランダムフォレスト)と比較するという構成になっている。
(1) QBoostベースのモデル
QBoostは、広く知られているように、GoogleとD-Waveの研究者によって開発された手法である。2値分類器による分類タスクを、QUBO(2次制約なし2値最適化問題)形式に変換することで、量子アニーラで扱える。本論文は、堕天使予測という分類タスクにおいて、アンサンブル学習が有効であるという事前の検証結果の下、古典アルゴリズムとしてランダムフォレスト、量子古典ハイブリッドアルゴリズムとしてQBoostを選択している。
「成功するアンサンブルを設計するための重要な課題は、ベースとなる学習器の多様性を確保すること」と述べる本論文では、異なるタイプの学習器を使用することで、多様性を確保している。具体的には、再現率に優れる決定木と、精度に優れるk近傍法を組み合わせたモデルを構築した(ロジスティック回帰、単純ベイズを含む4つの手法から、決定木とk近傍法を選択している。ただし、k近傍法の精度は、ロジスティック回帰、単純ベイズとほぼ変わらない(1%高いだけ)。その反面、再現率は2~4%低い)。
さらに、学習方法も工夫を凝らした。各学習器をデータセットの異なる履歴期間で学習させる。その理由を『弱学習器が、学習データセットの基礎となる異なる景気後退期と景気拡大期について独立して学習し、アンサンブルをさらに多様化することが期待される。さらに、学習器の各サブグループがデータのサブセットで訓練されるため、訓練時間が大幅に短縮される』と述べている。
(2) テンソルネットワークに基づくモデル
大規模なQUBOを、その構造に制限されることなく取り扱うため、テンソルネットワークに基づくモデルも使用する。本論文では、その理由を、❶構成上テンソルネットワークは、O(poly(N))個のパラメータにのみ依存し、多項式スケーリングが可能なため、量子コンピュータのエミュレーションに有用である。❷テンソルネットワークは、古典的および量子的な最適化問題を解くための自然なツールであることが証明されている、と説明している。
その上で、時間発展ブロック・デシメーション法(TEBD)に基づく最適化アルゴリズムを提案している。TEBDは、テンソルネットワーク、正確には行列積状態(MPS)によって、ステップ毎の時間発展の状態をシミュレートする。
【4】結果
(1) QBoostベースのモデル
㊀ ベンチマーク比較
50個の弱学習器からなるアンサンブル学習モデルで、そのk近傍法と決定木の割合は、ハイパーパラメータ最適化手順により最適に選択される。当該モデルは、ランダムフォレストと非常によく似た性能を達成した。ギャップ[*19]が1%以下である場合、精度 = 27.9 ± 0.09%に達し、同じ再現率R = 83%の、ベンチマークしきい値(精度) = 28.0 ± 0.07%に近い結果を得た。実行時間は、ランダムフォレスト3時間以上に対して、当該モデル約50分である。これらの結果は、ランダムフォレストの1200の学習器に対して、50の学習器で得られている。
本論文では、この差を「モデルの解釈のしやすさに大きく関わってくる」と評価している。「新しい未知の点に対して出力されたモデルの判断は、より簡単に遡ることができ、ユーザーにより良く理解される」からである。
㊁ 将来予測
k近傍法と決定木の構成が異なる2つのサブモデル(タイプ1、タイプ2)の将来予測を行う(タイプ1及びタイプ2は、説明の都合上、本稿で独自に付けた)。タイプ1は、60量子ビットのハードウェア性能迄で、可能な限り最高の性能を得るように最適化したサブモデル。一方タイプ2は、最適性能とより好ましいスケーリング傾向の二兎を追ったサブモデル。性能評価は、再現率を83%で固定した場合に達成される精度の値である。また、将来予測は、スケーリング傾向比較のため、線形外挿を適用している。
タイプ1は、150量子ビット程度でランダムフォレストを上回ると予想される。タイプ2は、ランダムフォレストを約282量子ビットで、タイプ1を約342量子ビットで上回ると予測されている。
(2) テンソルネットワークに基づくモデル
ブースティングに基づく当該モデルは、現在中性原子QPUでは直接最適化できない非対角要素が負値を持つ、QUBOの最適化を活用したモデルである。学習器15程度で、ランダムフォレストと並ぶ。学習器90の場合で、平均精度29%、再現率83%に達する。実行時間は、ランダムフォレスト3時間以上に対して、当該モデル20分のオーダーである。
【5】考察
(1) 堕天使の予測は、データが不均衡であるから、そもそも難しい(倒産の予測も、同じ理由で難しい)。先にあげた論文[*18]でも、有効なモデルを構築できない、と結論している。それゆえ、古典アルゴリズムと比べて、量子アルゴリズム(正確には、量子古典ハイブリッド及び量子インスパイヤード・アルゴリズム)が優れた性能(より高い精度)が示さなくても不思議はない。そういう状況で、以下を背景に、実行時間を短縮できる具体策を提示したことは、評価できるだろう:『NP完全問題を量子コンピュータは効率的に解けない(と目されている)が、十分に良い近似解には、古典コンピュータよりも、速く到達できる(という証拠が蓄積されつつある)』。
(2) 古典アンサンブル学習のランダムフォレストと量子的アンサンブル学習のQBoostを比較して、「後者が優秀な成績を上げたから、量子アルゴリズムが優れている」という言い分は、間違いではないにしても、腹落ちしないだろう。他に優れた古典アルゴリズムが存在するかもしれない(ただし、この議論は、金融に限らず全ての分野で、常に存在している)。また、テンソルネットワークに基づくアルゴリズムは、量子アルゴリズムではない。従って、金融実務(の一部)において、量子アルゴリズムの優位性が示されたとの主張は、hype(あるいは焦り?)であると感じる。
(3) なお、米コンサルティング・ファームのマッキンゼーは、21年12月のレポート[*20]で、フォール・トレラント量子コンピュータが実用化されれば、①信用リスクマネジメント、②市場リスクマネジメント、③サイバーリスク管理、④(資金洗浄等)金融犯罪の低減、が収益をもたらすと予測している。金額的インパクトは①>②>③>④である。
【0】はじめに
Ⅳで先述の通り、仏クレディ・アグリコルCIBは、金融実務における量子コンピューティングを使用した概念実証が、決定的な結果をもたらしたと発表した(23年1月26日)[*16]。金融商品の評価並びに信用リスク評価に関する概念実証を2021 年 6 月に開始していた。信用リスク評価に関する概念実証をⅣで紹介した。
ここでは、金融商品の評価に関する概念実証を紹介する。2つのモデルを2つの論文[*21](以下、先行論文)及び[*22](以下、本論文)でそれぞれ扱い、従来手法と比較している。
【1】先行論文と本論文の主張
先行論文及び本論文の主張は、以下の通り:従来手法との比較において、❶同じ精度を達成するのに必要なパラメータ数を大幅に削減した、❷同じパラメータ数で、高速化を実現した。
【2】金融工学としての事前整理
(1) 解題
標準的な、前方後退確率微分方程式(FBSDE)に対応する偏微分方程式は、2次微分において非線形となることはできなかった。つまり、確率微分方程式と偏微分方程式(PDE)との対応関係は、準線形偏微分方程式に留まっていた。Patrick Cheridito(米プリンストン大)他による論文[*23]では、 ジェネレータ[*24]に2次依存性を持つFBSDEを導入することで、両者の関係を、非線形(放物型)偏微分方程式にまで広げた。ジェネレータに2次依存性を持つFBSDEを、2次後退確率微分方程式(2BSDE)と呼称している。
PDEが適切なリプシッツ条件(と放物型であることの条件)及び、粘性解理論からの比較定理(粘性解の一意性定理)を満たす場合、2BSDEの解が存在する。このことは、元のPDEが一意の連続粘性解を持つことを意味している。
(2) 対象としたモデル
非線形にまで拡張された結果を受けて、先行論文及び本論文では、ブラックーショールズーバレンブラット・モデルとヘストン・モデルを適用対象とした。ブラックーショールズーバレンブラット・モデルは、非線形に拡張したブラック・ショールズモデルであり、ヘストン・モデルは、パラメトリックな確率的ボラティリティ・モデルの一つである。両モデルとも解析解が存在するため、提案する新しい手法と従来手法の比較は容易である。
ブラックーショールズーバレンブラット・モデルは、資産価格のボラティリティが時間的に一定であると仮定している点に問題がある。この問題を克服するために、本論文では、ヘストン・モデルを扱った。
【3】解法としての事前整理
(1) 解題
FBSDEの素直な解法は、(有限)差分法であるが、差分法には次元の呪いがつきまとう(もちろん、差分法に限定されない。有限要素法でも同じである。ちなみに、数値屋さんで、有限差分法とフルネームで呼ぶ人はいない)。この場合の次元とは、対象となる資産の数である。資産が株式であれば、銘柄数ということになる。次元の呪いを回避する方法として、深層ニューラルネットワーク(DNN。ただし、この文脈において、より正確にはPINN)が注目されており、100次元のヨーロピアン・コールオプションのプライシングなどが行われている。PINNについては、こちらを参照。
先述の通り、PDEの解が得られれば、2BSDEの解も得られる。その逆も然りである。先行論文・本論文は、❶「オイラー丸山近似により離散化した2BSDE(支配方程式)+終端条件」を損失関数(の構成要素)とする最適化問題を解き、❷2BSDEの解からPDEの解を求めるという、枠組みを採用している(❶における、損失関数を構築するアプローチは、先行論文と本論文で正確には異なるが、本質的には同じである)。
先行論文及び本論文の問題意識は、従来の深層学習を用いた手法では、計算量が多く、メモリーを食い過ぎるということである。解決策として、先行論文及び本論文では、DNNをテンソル化ニューラル・ネットワーク(TNN)と呼ぶものに変換することを提示している。DNNをTNNに置き換えることで、必要なパラメータ数が減り、メモリー消費が抑えられる、という理屈である。
(2) テンソル化ニューラル・ネットワーク
全結合層の重み行列をテンソルネットワークで置き換えることにより、ニューラルネットワークをテンソル化する。以下、テンソル化ニューラル・ネットワークをTNN、テンソル化した層をTN層と呼ぶ。先行論文・本論文ともに、結合指標に沿って行列積演算子(MPO)を縮約させ、TN層に対する重み行列を、新たに作る。以下、この重み行列を、TN層の重み行列、と呼ぶ。
TN層の重み行列の初期化は、全結合層の重み行列の初期化と同じ手続きを実施する。TN層の重み行列に、入力ベクトルを乗じて出力ベクトルが得られる。出力ベクトルに、活性化関数を適用し、TN層の前方パスを終了する。
(先行論文・本論文で)TN層の重み行列は、物理次元をdとするとd2×d2次元であり、d4個の要素を含む。この要素は、結合次元をχとしたとき、2χd2個の学習可能なパラメータを持つ。χ = d2/2でMPOを初期化した場合、d2個のニューロンを持つ全結合層(つまり、従来の深層ニューラルネットワーク、DNN)と同じ数のパラメータを持つ。χ < d2/2であれば、d4 - 2χd2より少ないパラメータで構成され、DNNよりパラメータを節約できる可能性が生じる。
上記の方法でTN層を実装し、TensorFlowやPyTorchのような自動微分をサポートする機械学習ライブラリを用いれば、DNNの全結合層と同様の方法で、TN層の重み行列を最適化して、TNNを学習させることができる。
なお本論文では、重み行列に初期化について、テンソル化ニューラル・ネットワーク・イニシャライザー(TNNI)と呼ぶ、異なる別の取り組みを実施している。しかしTNNIは、TNNに比べて、性能が劣ることが示されているため、割愛する。
(3) TNNがDNNより効率的と考えられる理由の整理
❶MPOとは、すなわち行列の効率的な表現である。dn×dn行列は、特異値分解により、nサイトのMPOに分解(テンソル化)することができる。相互作用が近接的である現実的な物理系では、比較的少数の特異値のみを考慮して縮約したテンソルが、十分に良い近似となっていることが知られている。つまり、より効率的な行列の表現を見つけることが可能である。金融工学も、現実的な物理系と同じであると仮定すれば、TNNはDNNよりも効率的であることが期待できる。
❷次のような、説明も可能であろう。TN層に対する重み行列の行列要素間には、相関がある。物理的に表現すると、行列要素がエンタングルしていることを意味している。つまり、より豊かな表現力を持っていることを意味している。先行論文・本論文では、この相関の存在により、損失関数の収束が加速されている、と述べられている。
【4】先行論文と本論文の結果
(1) 先行論文の結果
TNNとDNNの比較:同じ精度で、大幅に(約1/3に)パラメータ数を削減できた。同じパラメータ数では、(最大32.8%の)高速化を実現した。
先行論文では、ブラックーショールズーバレンブラット・モデルに加えて、ハミルトン・ヤコビ・ベルマン方程式に対するTNNのテストも行っている(ただAppendixの扱い)。TNNは、同じパラメータ数のDNNを収束速度の点で上回った(収束にかかる時間が63%短縮される)
。
(2) 本論文の結果
❶ セッティング
① ヨーロピアン・オプション
無リスク金利0%、原資産価格の初期値1、ボラティリティ20%、ブラウン運動の相関係数-0.5。ヘストン・モデルに現れる、いわゆる正の定数は、省略した。時間領域[0, T]は、N = 500の等間隔の区間に分割する。ペイオフ構造の単純さを考慮して、隠れ層は2層。
損失関数の表現は、平均二乗誤差(MSE)ではなく、log-cosh関数を使用している。サイズ100のバッチと10-3の固定学習率で、最適化アルゴリズムにはAdamを使用している。
② バミューダン・オプション
バミューダン・オプションとは、満期日前に権利行使が可能なオプションのうち、その行使可能日が複数回、間隔をあけて設定されているオプションをいう。実際の金融商品としては、例えば、マルチ・コーラブル債やストックオプションが、バミューダンを含んでいる。
原資産価格の初期値100、行使価格100, 配当率10%, 無リスク金利 5%, ボラティリティ20%、 満期3年、行使可能回数9回(行使可能日の間隔は、均等なので、4か月に1回)。
損失関数には平均二乗誤差(MSE)を使用。10-3の固定学習率で、最適化アルゴリズムにはAdamを使用。活性化関数は、Leaky ReLUを採用している。
❷ 結果
①DNNとTNNの比較
TNNは同じニューロン数でDNNと比較してメモリを節約できるだけでなく、同じ数のパラメータとニューロンで分散を減らし、より速く収束させることができる。
② 実行時間の比較
TNN は、同じパラメータ数のDNN より著しく速く(最大で 12 倍速く)収束する。
③ バミューダン・オプション
結論としては、2つの主張を展開している:i)TNNの優位性を適切に定量化するためには、より多くの調査が必要である。ii)古式ゆかしいLongstaff-Schwartz法では、計算コストが指数関数的に増加する。一方、TNNは物理次元dに対して、二次関数的に増加するに過ぎない。
【5】考察
(1) 量子アルゴリズム・古典アルゴリズムの優位・劣位という議論ではなく、金融実務において注目されているXVAに、適用可能な手法を提示しているという点に注目すべきかもしれない。
(2) 金融実務において、後退確率微分方程式(BSDE)が現れるケースとして、近年最も注目されている分野がXVAである。XVAのXは、案の定、総称を意味する。CVA(信用評価調整:Credit Valuation Adjustment/取引相手の信用コストを調整)から始まって、少なくとも、DVA(Debt Valuation Adjustment/自社の信用コストを調整)、FVA(Funding Valuation Adjustment/無担保取引の調達コストを調整)、KVA(Kapital Valuation Adjustment/規制資本の調達コストを調整(言わずもがなCapitalだとCが被るので、Kにしている))、MVA(Margin Valuation Adjustment/変動証拠金に加え、当初証拠金を調達するコストを調整)、CTDVA((Cheapest To Deliver Valuation Adjustment/適格担保の通貨選択オプションに関連するコスト調整)、がXVAに含まれる。
はじまりは、やはり2007~2008年の金融危機である。greedy!なデリバティブ取引におけるカウンターパーティ・リスクをどのように管理すべきかという議論の結果、カウンターパーティの信用力に応じて価格を調整するCVAは、市場慣行となった。DVAは、IFRS13で求められている。
代表的なXVAであるCVAの価値評価は難しいが、その理由を、木で鼻をくくった言い方で説明すれば、「非線形だから」となるだろう。計算手続き的にいうと、入れ子構造になっているから、という説明も可能だろう。数学的には、CVAは、BSDEを解くことで得られる。
従来は、Longstaff-Schwartz法、モンテカルロ法、確率メッシュ法(並びに、複製ポートフォリオによる偏微分方程式のアプローチを用いた手法[*25])などが適用されてきた。ここで、紹介した、テンソル化ニューラルネットワーク(TNN)は、適用可能なはずである。今後、成果が発表されると思われる。
【0】はじめに
米国の量子ソフトウェア・スタートアップQC Ware、スイスの製薬大手ロシュ及び仏国立科学研究センター、英エディンバラ大学の研究者は「医療画像解析において、量子版トランスフォーマーが古典版トランスフォーマーよりも優れていることを示した」と発表した(プレスリリースは、23年3月17日。そう主張する論文[*26](以下、本論文)をarXivにて公開したのは、22年9月16日)。
【1】本論文の主張
本論文の主張は3つある:(1)トランスフォーマーの学習において必要な、線形代数計算を量子的に行うことで、古典トランスフォーマーに対して2次加速を達成した。(2)量子版トランスフォーマーに必要なパラメータは、古典版に比べて少なく、過学習の抑制が期待できる。(3)量子版の精度は、古典版と同等以上である。なお(1)で「トランスフォーマーの学習において必要」と書いたが、「トランスフォーマーの枢要である注意機構の計算において必要」が、正確である。また、(3)の主張は額面通りには、受け取れない。
付け加えると、QC Ware他の研究者は、自身のアプローチをNISQ(Noisy Intermediate-Scale Quantum device)フレンドリーである、とも主張している。
【2】事前整理
アーキテクチャ的に見ると、量子機械学習は、古典的機械学習アルゴリズムの性能を向上させるために、線形代数に対する効率の良い量子計算を使用する。ハードウェア的に見ると、量子機械学習は、量子回路を使って、ニューラルネットワークを構成し、機械学習(深層学習)を実行する。
本論文における古典的機械学習モデルは、「機械学習・深層学習に革命を起こした、畳み込みニューラルネットワーク(CNN)を凌駕して、衝撃を与えた」ニューラルネットワーク、トランスフォーマーである。
(1) トランスフォーマー
トランスフォーマーとは、入力データ全体を要素ごとに処理しながら、大域的な文脈を考慮する注意機構を利用した、ニューラルネットワークである。なお、トランスフォーマーは幅広い分野で応用展開されており、画像認識タスクに使われるトランスフォーマーは、ビジョン・トランスフォーマーと呼ばれる。
画像認識タスクをもう少し具体的に述べると、まず、画像を小さなパッチに分割する。そしてトランスフォーマーは、パッチ単位の演算を行うのではなく、パッチごとに”アテンション係数”と呼ばれる重み係数を学習し、各パッチが画像の残りの部分に払う”アテンション”を推測する。画像認識や自然言語処理の場合、文脈が重要であり、トランスフォーマーは、注意機構を持たないCNNよりも、文章の一部や画像間の大域的な相関を捉えることができる(と考えられている)。先にあげたアテンション係数で、大域的相関を捉えている。
[余談]なにかと話題のGPT(オープンAI)のTも、GPTの陰に隠れてしまった感のあるBERT(グーグル)のTも、トランスフォーマーのTである。
(2) 量子線形代数
線形代数計算を量子的に行う、量子線形代数では、HHL(Harrow,Hassidim & Lloyd)アルゴリズムが有名である。線形回帰やサポートベクターマシンを使った回帰あるいは分類タスクを、HHLアルゴリズムを使って量子的に実行すると指数的高速化が得られることが知られている。ただし、HHLアルゴリズムは、学習データを行列形式で表したデータ行列が疎(スパース)である、あるいは低ランクであるという条件下でのみ、有効である。また、HHLアルゴリズムはNISQでは実行できない(とされているが、NISQで実装する研究も進められているようである[*60])。
本論文では、データ行列(医療画像)に制約を付けることなく、再構成可能なビームスプリッター(Reconfigurable Beam Splitter:RBS)ゲートからなるパラメトリック量子回路(PQC、量子計算の文脈では一般的にはansatzと呼ばれる)を使って、量子線形代数計算を行っている。そして、古典計算に対して、2次加速を実現している。
(3) MLP-Mixer
機械学習・深層学習の世界は新陳代謝が盛んであり、トランスフォーマーを超えるCNNの研究や、多層パーセプトロン(MLP)のみでもトランスフォーマーを超えるというMLP-Mixerの研究などもある。
MLP-Mixerは、畳み込みや注意機構を使用せずに、異なるパッチを混合(mix)する。まず、パッチを混合し、次に全結合層を使用して、パッチ単位の特徴を抽出する。先に言ってしまうと、後述する「複合トランスフォーマー」は、概念的にはMLP-Mixerと考えることもできる(と、本論文で述べられている)。
【3】モデルの説明
量子コンピュータで機械学習を行うには、古典的なデータを量子回路に読み込む必要がある(から、実際の量子計算には、余計な面倒がかかる!)。本論文では、(古典的データのスカラー成分をd量子ビットで構成される量子状態の振幅として利用する)振幅符号化を選択している(これは特別な選択ではなく、普通の選択)。データローダーの詳細は割愛して、モデルの説明を行う。
本論文で扱われている量子版トランスフォーマーは、本質的に、直交トランスフォーと、複合トランスフォーマーの2種類である。
(1)直交トランスフォーマー
本論文で、古典版トランスフォーマーの量子版と位置づけられているモデルである。❶特徴ベクトルとアテンション係数との積を足し合わせて、出力を得る。❷特徴ベクトルは、パッチiと学習可能な行列の積から計算される。❸アテンション係数は、パッチiとパッチj及び学習可能な行列の積から計算される。❶は古典的に計算される。❷及び、❸が量子的に計算されている(ソフトマックス関数の作用は古典的に行われる)。
なお、直交ペアワイズ・トランスフォーマーというモデルも、参考的(かませ犬的)に登場している。これは、同じパッチ同士でのみアテンション係数を計算するというモデルであるため、それほど意味はないし、古典版トランスフォーマーに比べて、精度も低い(故に、ここでは、独立して採りあげていない)。
(2)複合トランスフォーマー
複合トランスフォーマーは、古典的トランスフォーマーとは異なる手続きを行っている。すなわち、特徴ベクトルの計算、アテンション係数の計算、それらの線形和という手続きをとらない。代わりに、(n+d¦2)次元の行列・ベクトル乗算を行う。この行列・ベクトル乗算は、ベクトルと2次複合行列の乗算で、計算量はO((n+d)4)である。複合トランスフォーマーでは、量子トモグラフィ-を使って乗算結果を推定することにより、O((n+d)4)という古典的には困難な計算を実現している。ここで、nはパッチの数、dはパッチのサイズ(次元)、(n¦k)は2項係数である。また、k次複合行列とは、k次の小行列式を正方行列の形に並べて得られる行列を言う。複合行列を使うから、複合トランスフォーマーと呼ぶ(のだろう)。
複合トランスフォーマーは異なる手続きを採用するものの、トランスフォーマーの精神を受け継いでいる。複合行列の乗算という形で、パッチは、その大域的な文脈で重み付けされ、行列式を通じて勾配を共有している、からである。
同時に、MLP-Mixerの精神を受け継いでいるとも考えられる。複合トランスフォーマーは、次の❶と❷を、同時実行しているとも考えられるからである:❶パッチを混合する、❷全結合層を使用してパッチ単位の特徴を抽出する。
【4】セットアップ
(1)データセット(学習データ)
本論文では学習データとして、12種類のオープンな医療画像データセット・コレクションであるMedMNISTを使用している。MedMNISTは、画像モダリティの分類タスクのために標準化されており、それぞれ28×28ピクセルの医用画像で構成されている。詳細に言うと、PathMNIST、 ChestMNIST、DermaMNIST、OCTMNIST、PneumoniaMNIST、RetinaMNIST、BreastMNIST BloodMNIST、TissueMNIST、OrganAMNIST、OrganCMNIST、OrganSMNIST[*27]である。
(2)セッティングと評価指標
1⃣ サイズ28×28の入力画像に対して、サイズ7×7のパッチを16個抽出する。ニューラルネトワークは4層。すべてのパッチをニューラルネットワークの特徴抽出部分の次元に対応させる。その次元数は16。
2⃣ JAXパッケージを使用。最適化アルゴリズムはAdam。エポックは100、バッチサイズは32、学習率は10-3で、交差エントロピ損失を使って学習する。50と75エポック後に、0.1倍で減衰する。
3⃣ 評価指標は、 正解率ACCとROC曲線下面積(AUC)を採用。ベンチマークは、古典版トランスフォーマーである。
【5】本論文の結果
(1)計算量の削減
古典版注意機構の計算量は、特徴ベクトルの計算がO(nd2)、アテンション係数の計算がO(n2d)である。全体としてO(nd2+ n2d)となる。ここで、nはパッチの数、dはパッチの次元である。
量子版注意機構は、❶直交トランスフォーマーの計算量がO(d×log(d))であり、❷複合トランスフォーマーの計算量は、O((n+d)log(n+d))である。したがって、ともに2次加速を達成していると主張している。
(2)学習可能パラメータの数
古典版は、1層につき2×162=512。4層なので、2048(本論文では、2064となっている)、❶直交トランスフォーマーが、64パラメータ/層×4層=256。❷複合トランスフォーマーが、80パラメータ/層×4層=320。量子版は、圧倒的に少ない。
(3)精度
12個のMedMNISTの内、古典版トランスフォーマーの性能が最も高いデータセットは、5つある。具体的にはChest、OCT、Pneumonia、Blood、Tissueである。ACC、AUCとも最善である。ただし、BloodのAUCは複合トランスフォーマーと同スコアである。
直交トランスフォーマーの性能が最も高いデータセットは、3つある。ただし、 ACC、AUCともに最善のデータセットは、Pathだけである。他のRetinaとOrganSは、AUCのみが最善(最大)で、ACCは複合トランスフォーマーが最善(最高)である。
複合トランスフォーマーの性能が最も高いデータセットは、7つある。ただし、CC、AUCともに最善のデータセットは、4つだけである。具体的には、Derma、Breast、OrganA、OrganCである。先に述べた通り、BloodのAUCは古典版トランスフォーマーと同スコア。RetinaとOrganSはACCのみ最善である。
量子版トランスフォーマーは直交トランスフォーマーであるから、「量子版の精度は、古典版以下」がフェアな評価であろう。
【6】考察
1⃣ トランスフォーマーとMLP-Mixerの精神を受け継ぐ「複合トランスフォーマー」の精度は、古典的トランスフォーマーと同等以上、と言えるかもしれない。その計算量は古典的には実行困難であるが、量子的には実行可能というところがミソ。ただ、画像認識タスクで用いられる他の古典アルゴリズムと比べて、複合トランスフォーマーの精度が優れているか?という設問だと、答えはネガティブである。
2⃣【2】で「量子機械学習は、古典的機械学習アルゴリズムの性能を向上させるために・・・良い量子計算を使用する」と書いたが、本論文での性能とは、速度(高速化、ただし2次加速)ということになる。古典アルゴリズムが優秀過ぎるため、量子版が、精度で古典版を超えるのは難しい。
ちなみに、付録AではResNet(18、50)やAuto-ML(3種類)との比較も行われている(他論文から転載している)が、余裕で負けている。詳細に言えば、ResNet-18(28、224)、ResNet-50(28、224)、auto-sklearn、AutoKeras、Google AutoML Visionの7種類が、比較対象に加わっている。28とか224とは、入力画像の解像度である。先の7種類に、ビジョン・トランスフォーマー、直交トランスフォーマー、複合トランスフォーマーを加えた10種類に対して、単純にACC、AUCで最善の場合、1ポイントを与えてみる。すると、1位はAutoML Visionの9点。2位はResNet-18(224)の6点。複合トランスフォーマーは1点の同点7位。直交トランスフォーマーは0点の同点9位。
医療用画像解析で求められる性能は、速さより精度であると思われるから、この結果では、厳しいだろう。
〖1〗概要
Quantinuumの研究者による論文[*Supp-2](2024年6月6日@arXiv)では、新しい量子トランスフォーマー・モデルQuixer(QUantum mIXER)が紹介されている。古典(かつオリジナルの)トランスフォーマーの枢要は、(マルチヘッド)ドット積自己注意機構にある。Quixerは、トランスフォーマーの量子化に際して、ドット積自己注意機構の量子版を構築するのではなく『別のアプローチ』を採用した。その結果は、「(実用的な)言語モデリング・タスクを対象として、古典トランスフォーマーと比較し、同程度の性能が示された」というものである。
要諦は『別のアプローチ』が(そこそこ)機能したということである。つまりは、古典的トランスフォーマー・モデルの量子化研究に新しい一歩を記した、ことがポイント。古典越えは、射程外である(今後に期待というスタンス)。👉 深層学習モデルの古典版を量子版が超えることは、至難である(と認識している)。
〖2〗 別のアプローチ
トランスフォーマーが達成する高い性能は、自己注意機構に由来する。オリジナルのトランスフォーマーは、(マルチヘッド)ドット積自己注意機構を採用している(ドット積=内積)。ただ、自己注意機構をドット積ベースで構築する必然性は必ずしもない。Quixerでは、トランスフォーマーの量子化を、ドット積自己注意機構の量子化ではなく、別のアプローチを用いて実行する。
具体的には、まず、㈠ユニタリ演算子の線形結合(LCU)を使用して、トークン・ユニタリ🐾1の重ね合わせを作成する。トークン・ユニタリは、パラメータ付き量子回路(アンザッツ)として物理実装される。次に、㈡この重ね合わせに、非線形変換を適用する。非線形変換には、量子特異値変換(QSVT)を使用する。
ドット積自己注意機構(古典的トランスフォーマー)は、クエリー・ベクトルとキー・ベクトルのドット積を使用して、キャプチャされたペアワイズ相互作用によって重み付けされた、バリュー・ベクトルの合計によって機能する。一方Quixerは、複数のトークン間の相互作用を、それらの代表的なユニタリの合成を通じてキャプチャする。Quixerでは、コンテキスト内のすべてのスキップkグラム間のペア🐾2ワイズ相互作用が計算される。
なお、ゲート複雑度は、O(dngl)である。ここでdは実装する多項式🐾3の次数、nはシーケンスの長さ、gはゲート個数、lはg/量子ビット数。
🐾1 ユニタリ行列として符号化された、ベクトル化トークン。
🐾2 k=2のスキップ”バイ”グラムのペアで説明すると、隣接している必要はないトークンのペアが、 スキップ”バイ”グラムのペアである。
🐾3 量子特異値変換に現れる多項式。
〖3〗比較検証
1⃣ データセット
HuggingFace データセット パッケージから取得したPenn Treebank データセット。このデータセットは、966,000個の学習トークン、77,000個の検証トークン、86,000のテスト トークンで構成される。
2⃣ シミュレーション環境
QuixerはTorch モジュールとして実装され、Torch ネイティブの量子計算フレームワークである TorchQuantumを使用してシミュレートされた。量子ビット数は6。
3⃣ ハイパーパラメータ等
トークンの埋め込みサイズ(次元)として 96 と 128 を使用する。 オプティマイザーはAdam。学習率は、コサイン アニーリング スケジュールに従って変化させた。エポック数は30(NVIDIA A100で3 時間 45 分)。バッチサイズは1,024🐾4。
🐾4 32コンテキスト/バッチ、32トークン/コンテキスト。32×32=1,024。
4⃣ 比較指標
パープレキシティを採用。パープレキシティ=2交差エントロピー
5⃣ 比較したモデル
PyTorchパッケージで提供されているLSTMおよびトランスフォーマー、およびFNet🐾5のPyTorch実装。
🐾5 FNetは、マルチヘッド自己注意機構を、入力行列に適用された2次元フーリエ変換に置き換えたトランスフォーマーの簡易版。
6⃣ 結果
次元数(96及び128)に関わらず、PPLが小さい順に、トランスフォーマー>FNet>Quixer>LSTMである。つまり、Quixerは古典トランスフォーマーは、言うに及ばず、その簡易版FNetにも及ばないという結果。注意機構がないLSTMには勝っているので、おそらくQuixerには注意機構らしきものが導入されていると期待できる(かもしれない)。なお、すべての結果は、ショット数10の実行の平均値である。
【0】はじめに
量子深層強化学習によるヘッジが、(文字通り古典的な手法である)デルタヘッジよりも優れている、と主張する論文[*28](以下、本論文)がarXivにて発表された(23年3月)。期待累積リターン及びポートフォリオ損益(PnL)を指標として用いた。
本論文は、JPモルガン・チェース銀行、米QC Ware、仏国立科学研究センターの研究者が作成した。Ⅵとは、ニューラルネットワークの量子化という意味合いで、同じ枠組みである。QC Wareと仏国立科学研究センターは、共通している。
【1】本論文の主張
本論文の主題は、量子化された分布強化学習を使ったディープ・ヘッジング (量子ディープ・ヘッジング)は収束性が高い、という主張である(と理解している)。具体的には、「量子ディープ・ヘッジングは、コスト関数の勾配の分散が、時間ホライズンTで多項式的に減衰する」ことを保証する。
量子ニューラルネットワーク自体、 一般に学習が難しく、不毛な台地(バレンプラトー、とも呼ばれる)や勾配消失の問題に遭遇することが多い。さらに、過去のヘッジ行動に依存する深層学習を用いたディープ・ヘッジングは、収束が遅い(あるいは収束しない)ことが問題とされている。これに対して、量子ディープ・ヘッジングは、収束性が高いと主張してるわけである。
加えて、表現能力が高い(量子ビット数で指数関数的に減衰する誤差で、真の分布を近似できる)、汎化性能が高い(真の最適な表現可能なモデルに、高い確率で収束することを保証する)と主張している。
【2】事前整理
次項で、本論文の枠組みを述べるが、いくつか事前整理を行う。
(1) 学習モデル的事前整理
1⃣ 強化学習
長期間に渡る期待報酬を最大化するポリシーを見つけることが、強化学習の目的である。本論文では、以下2つのアルゴリズムを採用している。ちなみに、ポリシーには、方策という訳語が、一般に用いられている。政策というケースも散見される。腹落ちという点では、戦略という単語でも良いかもしれない。
❶方策探索アルゴリズム
このアルゴリズムでは、ニューラルネットワークを使って、方策をモデル化する。そして、パラメータ空間における、長期期待報酬の勾配を直接計算して(つまり、勾配降下法を使って)、パラメータを更新する。方策損失関数を最小化することで、パラメータが最適化され、方策も最適化される。
❷アクター・クリティック・アルゴリズム
普通に訳せば、クリティックは批評家・評論家であるが、アクター・クリティック・アルゴリズムの文脈では、クリティックは価値表現モデルを指す。アクターは、方策モデルを指す。
このアルゴリズムでは、方策モデルと「独立かつ同時並行」で、価値表現モデルを学習し、方策の勾配計算を行う。方策と価値関数の両方が、ニューラルネットワークを使ってモデル化される。方策の勾配計算は解析的には困難であるが、価値関数がニューラルネットワークで近似されているので、この計算が容易に行える。方策勾配が得られれば、勾配降下法の要領で、パラメータが更新される。損失関数を最小化することで、価値パラメータ及び方策パラメータが最適化され、方策が最適化される。方策を専門家の経験、価値関数を専門家の勘に例える[*29]とわかりやすいかもしれない。経験と勘の両方を駆使して、正解に近づいていく学習法というわけである。
なお、よりシンプルな、モンテカルロ方策勾配法では、価値関数を報酬で置き換える。
2⃣ 分布強化学習(distributional reinforcement learning)
ある行動をしたことで得られる期待累積リターン(収益)を、確率的に捉える。もう少し正確に言うと、収益を確率分布からのサンプリング結果と考える。つまり、分布強化学習では、収益を学習するのではなく、収益が従う確率分布を学習する。
分布型ではない強化学習でも、収益の「平均値」を使用する。これは、収益の確率分布を正規分布と見做している、と考えることができる。確率分布を正規分布と決め打ちせずに推定する方が、表現力は高いため、高い精度が期待できるだろう。
(2) 金融的事前整理-ディープ・ヘッジング
本論文におけるヘッジとは、金融派生商品による発生する損失を(しばしば、原資産のみを使って)カバーするという意味のヘッジである。理想化された摩擦のない市場において、デリバティブの最適なヘッジ戦略を提供することは、容易である。一方、実際の不完全市場では、取引コスト・市場への影響・非流動性、その他の現実制約を考慮して、ヘッジ戦略を適応させる必要がある。ディープ・ヘッジングは、この困難な問題を解決するために、深層学習を適用した枠組みである。
1⃣ 計算困難性の回避
ディープ・ヘッジングは、問題の定式化としては、損失リスク最小化問題として定式化される。つまり、損失リスクを最小化するように、ヘッジ戦略(ポリシー)を決定する問題として、定式化される。先述の通り、理想化された市場で、これは容易であるものの、実際の市場では、難しい。通常、リスク中立価格に、取引コスト等(XVAを念頭に置くと、多種多様なコストが存在する)をチャージした価格をヘッジ対象の現在価値とみなすが、このような現実制約を加味することは、(数値)計算上の困難をもたらす。そこで、数値計算を、深層学習で代替して、この困難を回避しようとするアプローチが、ディープ・ヘッジングである。
2⃣ ディープ・ヘッジング
ディープ・ヘッジングは、①「ヘッジ戦略を、大量のパラメータを持つ関数だと仮定」した上で、②「ヘッジ戦略をニューラルネットワークで表現」し、③「深層学習を用いて、損失リスクを最小化するように、パラメータを決定」する枠組み、と定義できる。現在のヘッジ行動が、ニューラルネットワークの入力となる。損失関数は、-1×ポートフォリオ価値の期待効用、であり、ポートフォリオ価値=オプションのペイオフ+原資産の価格変動により発生する損益-取引コスト、である。損失関数を最小化するパラメータを見つけることで、最適なヘッジ戦略を見つけるという流れになる。
ディープ・ヘッジングを使えば、複雑な条件下であっても、ヘッジ戦略の構築が可能になると期待される一方で、学習が過去のヘッジ行動に依存するため、学習が難しい(なかなか収束しない)ことが問題となる。
3⃣ 強化学習を用いたディープ・ヘッジング
深層学習を用いたディープ・ヘッジングの収束性が低いという問題に対する解決策の一つが、強化学習を用いたディープ・ヘッジング(正確には、深層強化学習を用いたディープ・ヘッジングと表現すべきであろう)である、と考えられる。
強化学習を用いたディープ・ヘッジングヘッジグでは、方策=ヘッジ戦略とおく。最適な方策を見つけることが、最適なヘッジ戦略を見つけることにつながる。最適な方策を見つける方法として、本論文では、方策探索アルゴリズムと、アクター・クリティック・アルゴリズムを採用している。
【3】本論文の枠組み
(1) 概要
本論文は、パラメータ化された量子回路に基づく量子ニューラルネットワークを使って、分布強化学習を用いたディープ・ヘッジングを行う手法を提示している。バージョンアップ的に表現すると、深層学習→強化学習→分布強化学習→量子化分布強化学習である(邪推であるが、有用な量子アルゴリズムを探している中で、分布型の相性が良いと認識したため、強化学習→分布強化学習という流れになったのかもしれない)。
一般に、量子ニューラルネットワークは、勾配の分散が量子ビットの数に応じて指数関数的に減衰し、不毛な台地や勾配消失の問題に遭遇する[*30]。本論文では、勾配の分散が量子ビット数に対して、多項式で減衰するように、量子層を設計したことで、効率的に学習可能な量子ニューラルネットワークを構築できた、と主張する。
さらに本論文は、量子コンピューターは分布強化学習に適している、と主張する。その理由を、「各量子回路は、指数関数的なサイズ分布間のマッピングを明示的に符号化し、量子回路の測定により、そのような分布からのサンプルが得られる。これらのサンプルを使用して、分布全体の期待値を単純に学習したり、全範囲の関連部分集合に制限された期待値など、分布に関する追加情報を柔軟に取得したりできる」とする。
(2) 量子層の設計
本論文では、 古典的ニューラルネットワーク・アーキテクチャの、自然な量子化を提供するために使用できる2 つの異なるタイプの量子層を導入している。直交層と複合層である。古典的ニューラルネットワークの線形層が、直交層と複合層に置き換えられて、量子ニューラルネットワークが構築される(直交層は、参考として示す)。
複合層は、入力データを二値(binary)で符号化する。ニューラルネットワークが探索するヒルベルト空間のサイズは、符号化した入力データに対して、指数関数的にスケールする。そのため量子回路は、古典的にシミュレートすることは難しい。つまり、複合層は、本質的に量子的性質を持つ。にも関わらず、複合層では、勾配の分散は指数関数的に減衰しない(ように設計した)。それが、特徴となっている。
[参考] 直交層
直交層は、入力データを単値(unary)で符号化する。ニューラルネットワークが探索するヒルベルト空間のサイズは、符号化した入力データに対して、線形にスケールする。そのため量子回路は、2次オーバーヘッドの計算量で、古典的にシミュレート可能である。
(3) 分布強化学習を用いた量子ディープ・ヘッジング
本論文では、1⃣標準的な量子強化学習手法をディープ・ヘッジングに適用しようとすると、解決すべき問題がいくつか存在することを提起し、2⃣解決策を示している。
1⃣ 解決すべき問題
❶ほとんどの量子ニューラルネットワークモデルが、離散行動空間にのみ適用されているのに対し、ディープ・ヘッジは、制約付きの連続行動空間に適用されている。
❷量子方策または価値関数を学習するためのアルゴリズムは、(割引)ベルマン方程式を解くことに依存している。しかし、リスク調整された測定値の観点から定式化される、ディープ・ヘッジングにおいては、価値関数はベルマン方程式に従わない。
❸方策勾配と価値関数は、量子的に近似する必要がある。
2⃣ 解決策
本論文では、上記問題を、複合層を備えた量子ニューラルネットワーク・アーキテクチャと、アクター・クリティック・アルゴリズムを使用して解決している。
まず、行動が遷移確率に影響を与えない、つまり、取引行動が市場に影響を与えないと仮定している。このため、遷移オラクルは行動の量子符号化を必要としない。また、オラクルを介した報酬関数への量子アクセスを必要としない。このため、連続行動空間で定義される報酬関数に対して効率的である。
次に、価値関数(=期待累積リターン)が、カテゴリ分布を使用して表現できることを示すことにより、分布強化学習につなげる。そして、適切なユニタリ演算子(伝統的に、物理屋さんは「演算子」、数学屋さんは「作用素」という文言を用いる)と、オブザーバブルを構築することにより、リターンとリターンの確率分布を近似している。ちなみにオブザーバブルを日本語に訳すのは、難しい。
さらには、この近似において、㊀リターンが、もはや割引ベルマン方程式に準拠していないこと、㊁計算量が量子ビットの数に応じて指数関数的に増加すること、に対応する必要がある。本論文では、将来パスの集合を分割し、各部分集合内の分布の期待値を学習することで、対応している。方策とは独立したオブザーバブルに出力状態を射影することによって、将来パスの全ての部分集合での指数化されたリターンの期待値と、すべての将来パスでの全体的な期待値を正確に予測できる、としている。
【4】比較の結果
(1) 古典シミュレーションとNISQマシンによるエミュレーションの比較
上場株式を、権利行使価格K = 1 のヨーロピアン・コールオプション(売り持ち)でヘッジする。時区間(ホライズン)は、毎日のリバランスで30 取引日に設定された。ドリフトは0、ボラティリティは、20%で、満期は10日。比例取引コストは0.002とした。最適化アルゴリズムはAdamで、損失関数はフーバー損失を採用している。
❶ポリシー探索、❷(分布型でない)アクタークリティック、及び❸分布アクタークリティックという3種類のアルゴリズムが、期待累積リターンを指標として、比較された。計算は、①古典シミュレーションと、②ハードウェアノイズが含まれる、NISQマシン(Quantinuumのイオントラップ型量子プロセッサ)によるエミュレーション、の2パターンで実施された。その結果、①及び②ともに、❸が最も優れていた。
(2) ”古典的”なデルタヘッジと、量子強化学習によるヘッジの比較
❶ブラックショールズモデルによるデルタヘッジ、❷(分布型でない)アクタークリティック、及び❸分布アクタークリティックという3種類のアルゴリズムが、期待累積リターン及びポートフォリオ損益(PnL)を指標として、比較された(損益計算は、8本のパスに対して行われた)。❷と❸の計算は、①古典シミュレーションと、②NISQマシン(Quantinuumのイオントラップ型量子プロセッサ)による計算、の2パターンで実施された。
全体感は、❶に比べて、❷及び❸が優れていて、❸がやや❷を上回るという結果である。
【5】考察
(1) 他の事例が存在するため、量子アルゴリズムの必然性は問われる
一言で表現すれば、実務で使えるアルゴリズムを提示した、ということが本論文のウリであろう。しかし、ディープ・ヘッジングの収束性を改善するという目的であれば、深層学習の範疇(つまり、ヘッジ戦略をニューラルネットワークで表現する)で、[*31]がある。量子強化学習アルゴリズムの必然性は、要検討ということになるであろうか。
なお[*31]の貢献は、以下の2点と思われる:❶収束しないという”最悪の”事態を避けることができる(のみならず、20倍以上高速に学習可能)な手法を開発した。これは、過去のヘッジ行動をニューラルネットワークの入力に使用しないことで、実現した(学習困難性の原因が「ニューラルネットのインプットが現時刻の保有株数に依存すること」であるという仮説を立てて、実証した)。❷指数型効用関数のもとでヨーロピアン・オプションをヘッジする最適戦略が、より一般の効用関数・幅広いオプションに対しても、最適ヘッジであることを証明した[*32]。
ちなみに、強化学習を用いたディープ・ヘッジング(分布型ではない、"期待型の”アクター・クリティック・アルゴリズム)[*33]も提案されている。後者では、ブラックモデルに基づくデルタヘッジと比較して、わずかに平均効用が上回った、というシミュレーション結果が示されている[*34]。有用性という意味では、厳しい結果であろう。
(2) さらに他のアプローチ
生成モデルでシナリオを生成し、シナリオ生成とヘッジ戦略の学習を逐次的に繰り返す、というアプローチも存在する。このアプローチも、強化学習を用いたディープ・ヘッジングと呼ばれているようである[*35]。
市場データは、㊀再現性に乏しく、㊁機械学習に必要なデータ量が確保し難く、㊂ランダムウォークを示す、という[*36]不利な状況を覆す指し手候補として、ボルツマン・マシンを用いたディープ・ヘッジングは、興味深いと思われる。
【参考資料】
西野友年・大久保毅、テンソルネットワーク形式の進展と応用、日本物理学会誌 Vol. 72, No. 10, 2017、pp.702-711 https://www.jstage.jst.go.jp/article/butsuri/72/10/72_702/_pdf
【0】はじめに
創薬において、機械学習・深層学習が果たす役割は、ますます大きくなっている。敵対的生成ネットワーク(GAN)は、創薬分野で最も成功した生成モデルの 1 つと見做されている。米国の創薬スタートアップ、インシリコ・メディシンの研究者他は、「量子古典ハイブリッドGANが、GANよりも優れている」と主張する論文(以下、本論文[*37])を公開した(23年5月13日、受付日は4月12日)。インシリコについては、[*13]も参照。
米国の量子ソフトウェア・スタートアップ、ザパタ・コンピューティングは、同社の調査レポート[*38](23年1月)において、「生成モデルが、量子力学の実用的な優位性をもたらす最も有望な手段であることが明らかになった」と明らかにしている[*39]。本論文の著者に名を連ねるアラン・アスプル=グジックは、ザパタの共同創業者である。
【1】本論文の主張
本論文は、GANの構成要素を部分的に量子化した量子古典ハイブリッドGANは、古典GANより、(1)優れた薬物特性を示す小分子を生成することができる、(2) 学習可能なパラメーターの数が、大幅に少ないにもかかわらず、有効な小分子を生成できる、と主張した。一方で、(3)量子古典ハイブリッドGAN は、ユニークで有効な小分子を生成するという点で依然として課題に直面している、とした(ユニークとは、重複なく生成するという意味である)。
なお、本論文におけるモダリティは低分子化合物であり、医薬品候補物質の発見を対象としている(※本稿では、小分子と低分子という用語は、それほど意識することなく、混同して用いている)。
【2】事前整理
(1) 先行研究の整理
本論文は、創薬における主な生成機械学習アルゴリズムを、以下のように整理している:㊀進化アルゴリズム(EA)、㊁リカレント ニューラル ネットワーク (RNN) (ゲート付きリカレント ユニット (GRU) や長短期記憶 (LSTM) など)、㊂オートエンコーダー (敵対的オートエンコーダー(AAE)、及び変分オートエンコーダー (VAE))、㊃敵対的生成ネットワーク (GAN)。
GAN は、様々なタスクのデータ分布を模倣したデータを、生成する場合に顕著な結果を示しており、 創薬分野においても、最も成功した生成モデルの 1 つと言われている。過去に提案されてきたアーキテクチャとして、以下があげられている:❶生成テンソル強化学習 (GENTRL)、❷目的強化敵対的生成ネットワーク (ORGAN)、❸LatentGAN、❹MolGAN。
❶及び❷は、GANと強化学習(RL)アルゴリズムを組み合わせている。❸は、オートエンコーダーとGANを組み合わせている。❹は、グラフ構造データの生成に取り組んだ最初の GANである。QM9データベースでの実験で、ほぼ 100% 有効な化合物を生成することが実証されている。
なお、MolGANで生成された分子は、(GAN+RLという意味で、同系統の)ORGANで生成された分子よりも、優れた化学的特性、特に合成性と水溶性を備えている、とされる。
(2) MolGAN
本論文における古典GANは、(先の❹で取り上げた)MolGANである。したがって、GANを特出しして、説明する。GANの構成要素は、ノイズ発生器、生成器、識別器と分けることができる。本論文では、一つの構成要素を、変分量子回路(VQC)で置き換えたハイブリッドGANを、MolGANと比較している。ちなみに、Molecular(分子)GANなのでMolGANであり、小分子が対象である[*39]。
先述の通り、MolGANはORGANと類似性が高い生成モデルである。主な相違点は、以下の通り[*40]:①ORGANは、分子表現にSMILESを使っている。MolGANは、(無向)グラフを用いる。②ORGANは、強化学習のアルゴリズムとしてREINFORCEを用いている。REINFORCEは方策勾配法である。MolGANは、Deep Deterministic Policy Gradient(DDPG、日本語訳はない?)の簡易版を使っている。方策勾配法と付いているが、DDPGは、オフポリシーのアクター・クリティック法である。将来の期待報酬(の近似値)を最大化するために、決定論的方策勾配法を使用する。当初は、REINFORCEと確率論的方策勾配法を組み合わせていたが、行動空間が高次元なので収束が遅く、決定論的方策勾配法(つまり、Deterministic Policy Gradient)に切り替えた。
また、MolGANの主要構成要素である生成器と識別器は、WGAN(ワッサーシュタインGAN、正確にはimproved WGAN)を使って学習される。より正確には、生成器は、(improved)WGANの損失関数と強化学習の損失関数の線形結合で表される損失関数で学習される。
(3) モデルのまとめ
本論文で取り扱われるモデルを、まとめた。
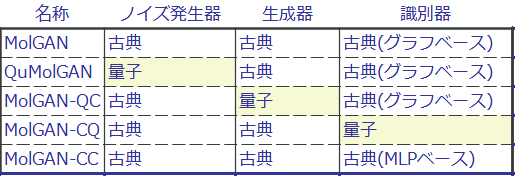
また、MolGAN-CCは、パラメータ数によって、さらに3つ(NR、HR、ER)に分かれている。
【3】実験及び成果
(0) ライブラリ
本論文における実験で用いられたライブラリは、Pennylane(カナダの光方式量子ハードウェア・スタートアップXanadu Quantum Technologiesが開発した量子機械学習ライブラリ)と PyTorch(メタが開発したパイソンベースの機械学習ライブラリ)である。
ちなみに(科学者以外なら、映画監督になりたかったらしい)アラン・アスプル=グジックはトロント大学教授(化学)であり、Xanaduの本社はトロントにある(もちろんPennylaneは、業界での評判が高い)。
(1) ノイズ生成器を量子化するインパクト:QuMolGANとMolGANの比較
①量子ノイズ生成器の学習率=0.04
②生成器と識別器の学習率=0.001
③エポック数=150
1⃣ ストレートな比較
❶比較用の指標は、以下の通り:医薬品らしさ(QED)、水溶性、SA(synthesizability:合成可能性)、及びカルバック・ライブラー(KL)情報量。
❷ノイズ生成器への入力次元が小さい場合(例えば2次元の場合)、ノイズ生成器を量子化したQuMolGANは、より優れた薬剤特性を持つ小分子を生成できる可能性がある。具体的かつ定量的に(ただし二重否定で言い表すと)、薬らしさを示す指標QEDが、0.4 未満である(つまり薬らしくない)小分子を生成する可能性は、MolGANに比べて低くなる。
一方、QuMolGANは、重複しない小分子を生成することが苦手で、KLスコアは低くなる。
2⃣ 目標指向ベンチマーク
❶比較用の指標は、以下の通り:validity(有効サンプル(今の場合、小分子)の割合)、uniqueness(重複していないサンプルの割合)、薬らしさ(QED)、水溶性、SA(synthesizability:合成可能性)、及びKL情報量。
❷ざっくり言うと、MolGAN=GAN+強化学習(RL)である。GANを強めにすると、有効なサンプル(小分子)の割合が増す。すなわちvalidityが高くなる。RLを強めにすると、例えばQEDが高い小分子が生成される(はずである)。両者のバランスをとることで、パフォーマンス(QEDと水溶性)が向上可能か、を試している。本論文では、これを、目標指向ベンチマークと呼んでいる。
具体的には、GAN(正確にはWGAN)の損失関数LGANとRLの損失関数LRLの線形和である、ノイズ生成器の損失関数
L=αLGAN+(1ーα)LRL
を使う(これは前述の通り、MolGANの生成器の学習に用いる損失関数と同じ形式である)。ハイパーパラメータであるαを動かすことで、GANとRLのバランスを変えて、パフォーマンスが向上するかを実験した。α=1.0、0.5、0.01で実験を行ったところ、α=0.01で、QuMolGANはMolGANを上回った。
一方で、validity、uniqueness、KLスコアはMolGANが上回った。
(2) 生成器を量子化するインパクト
ない(もちろん、本論文で”ない”とは書かれていない。どのように記述されているかは、本論文を読まれたし)。
(3) 識別器を量子化するインパクト
①ノイズ生成器のノイズは、正規分布からサンプリング
②生成器の学習率=0.0001
③エポック数=30
1⃣ ストレートな比較:MolGAN-CQ と MolGAN を比較
❶比較用の指標は、以下の通り:validity、uniqueness、QED、水溶性、SA、及びKL情報量。
❷MolGAN-CQ は、特に水溶性および SA において、より優れた薬物特性を持つ分子を生成できる(MolGANより値が高い)。
一方で、validity、uniqueness 、及びKL情報量において、値が低い。
2⃣ MolGAN-CC と MolGAN-CQ の比較
❶比較用の指標は、以下の通り:validity、uniqueness、QED、水溶性、SA、及びKL情報量。
❷MolGANの古典識別器を、グラフベースから、多層パーセプトロン(MLP)ベースに置き換えた、MolGAN-CCとMolGAN-CQを比較する。量子識別器は、グラフベースよりMLPベースに近いため、このように比較することがより公平である、と理由付けしている。
正確には、パラメータ数に応じて、MolGAN-CC-NR(パラメータの削減無し)、MolGAN-CC-HR(パラメータを削減)、 MolGAN-CC-ER(パラメータを大幅に削減)の3種類に分けて、MolGAN-CQと比較している。具体的なパラメータ数はNRで8万2千。HRで4万5千。ERで2万2千。それに対して、MolGAN-CQは50である。
結果は、 QED、水溶性、SAの全てにおいて、MolGAN-CC-ERが最も優れている。不思議な結果である。validityもERが最善で、uniquness及びKLスコアは MolGAN-CC-HRが最善である。
そして本論文では、MolGAN-CQのKLスコアが、MolGAN-CC-ERより高いことから、表現力において量子優位性が示された、と述べている。
【4】まとめ
(1) ノイズ生成器を量子化するインパクトは、薬物特性がやや向上している(顕著ではない)ので、若干あるように思える。
(2) 生成器を量子化するインパクトはない(と思える)。
(3) 識別器を量子化するは、薬物特性が向上しないので、ほぼないと思える。
(4) ただし、最も良い薬物特性を示すMolGAN-CC-ERのuniqunessは低すぎる(2.08)。故に、ERに、どこまで実用性があるのか疑問。そうすると実は、MolGAN-CQの薬物特性は悪くない。その場合は、識別器を量子化するインパクトはある、となる。
(5) あくまでsubject to (4)で、アブレーション分析的な見方をすると、一番効くのは、識別器の量子化ということになる。
(6) まとめのまとめ:validityとuniquenessでは見劣りするものの、ノイズ発生器と識別器を量子化したハイブリッドGANは、薬物特性に優れた分子を生成するという意味において、古典GANに勝っている(と思われる)。
【0】はじめに
世界の航空産業は(国際民間航空機関ICAOが旗を振って)、2050年までにネット・カーボン・ニュートラルな運航達成を目指している。飛行経路最適化は、(それによって燃料消費が減るため)ネット・カーボン・ニュートラルに貢献できると予想されている。さらに、飛行経路最適化は、気候変動の一因とされるコントレイル(飛行機雲)の形成を低減できる可能性がある、との期待もある👉[*62]。
米qBraid[*41]、米テキサス大オースティン校、米シカゴ大の研究チームは、3次元飛行経路最適化問題に、”古典アルゴリズムを量子的に改良したアルゴリズム”を適用した論文(以下、本論文[*42])を発表した(arXivにて23年4月27日公開)。(※古典アルゴリズムを量子的に改良したアルゴリズムは以降、量子改良アルゴリズムと呼ぶ。)
【1】本論文の主張
3次元飛行経路最適化問題(出発地と目的地の間で、最短経路を見つける問題)において、ウェイポイントの「数が少ない」と、最短経路をはじき出す時間は、量子改良アルゴリズムの方が古典アルゴリズムより短い、と主張している。ここで「数が少ない」とは、27未満、という意味である。これは、通常とは逆方向の高速化であり、不思議な結果である。
ウェイポイントとは、「緯度・経度・高度の情報で表される、航空路上の特定の位置」であり、航空交通管制の専門用語である。ちなみに、日本領空内にはウェイポイントが1,000以上あるらしい。
【2】事前整理
(1) 飛行経路最適化問題・・・スピーディーであることの重要性
飛行経路最適化は、衝突回避、燃料効率、環境への影響の最小化など、いくつかの重要な目的に対応するため、航空産業において重要な問題である。さらに、本論文によれば、飛行経路最適化はスピーディーに解決すべき課題である。
❶ 複雑さと高次元性
飛行経路最適化は、燃料消費量、飛行時間、航空機の重量、航空管制の制限など、多数の制約条件を持つ多変数最適化問題である。そして、この問題の複雑さは、多数の変数が相互に関連していることに起因しており、高次元の要因となっています。
❷ ダイナミックな環境とリアルタイムの制約
航空機は、風の変動、航空管制の制限、機器の故障など、急速に変化する状況下で運用されており、ダイナミックで不確実な環境を作り出している。このような複雑な環境では、リアルタイムに適応して対応できる正確なモデルやアルゴリズムの開発が必要である。航空機は、飛行中に飛行経路や運航条件を決定しなければならないため、飛行経路最適化には、大量のデータを処理し、短時間で解を提供できる高い計算能力と高速アルゴリズムが必要である。
(2)最適化アルゴリズム・古典版
まず、目的関数について。飛行経路最適化問題の目的関数としては、飛行時間、燃料消費量、二酸化炭素排出量などが考えられる。本論文では、 燃料消費量を選択している。
方法論として分類すると、飛行経路最適化問題は、最適化法と非最適化法に大きく分けられる。本論文によれは、非最適化法はさらに、㊀機械学習を用いる方法、㊁メタ・ヒューリスティックな方法、㊂シミュレーテッド・アニーリング法、㊃グラフベースの方法、に分けられる。本論文では、㊃に属する「ダイクストラ法」を、古典アルゴリズムとして採用している。その理由としては、以下があげられている:
飛行経路最適化には、動的な重量の再計算が必要である。再計算が必要なのは、航空機の燃料消費は予測不可能で非線形であるためで、飛行中に調整を行わずに飛行経路を決定することは不可能である。ちなみに、燃料消費量(燃料流量)は、高度によって異なることはもちろんのこと、海面と陸地でもは異なる。このような事情から、飛行経路最適化問題に使用されている、一般的なアルゴリズムは、ダイクストラ法である。
ダイクストラ法は、与えられた出発地sと目的地dの間の最短経路を見つけるアルゴリズムで、1956年に、Edsger Dijkstraによって開発(59年に発表)された。数学的に言うと、飛行経路のネットワークは、有向無巡回グラフG(V,E)で表される。Vは頂点(ノード)、Eは辺(エッジ、枝とも言う)である。このアルゴリズムは、隣接する頂点を繰り返し探索し、各頂点への最短経路と距離を更新することで動作する。目的地までの最短経路が見つかったか、2頂点間に経路がないと判断された時点で、探索プロセスは終了する。
ダイクストラ法の重要な考え方は、探索すべき頂点の優先順位キューを維持することであり、頂点の優先順位は、出発地からの距離推定値で与えられる。アルゴリズムは、すべての頂点の距離推定値を無限大に初期化することから始まるが、出発地はゼロに設定される。その後、アルゴリズムは、優先順位が最も低い頂点を、優先順位キューから繰り返し抽出し、現在の頂点への距離に基づいてその近隣頂点の距離推定値を更新し、これらの近隣頂点を優先順位キューに追加する。
有向無巡回グラフG(V,E)に対するダイクストラ法の計算コストは、O(V2)である。しかし、フィボナッチ・ヒープ優先キューを使用すると、計算コストはO(E+V log V) まで低下する。現在のところ『これを上回る量子アルゴリズムは存在しない』。必要は発明の母(飛行経路最適化問題を迅速に解く必要性が高い)ということだろう。本論文は、そこにチャレンジ(?)している。
(3) 量子改良アルゴリズム
量子改良アルゴリズムでは、フィボナッチ・ヒープ優先キューを使用しない”オリジナルの”ダイクストラ法を、(本稿では、便宜上)最小値探索ステップと更新ステップに分ける。その上で、前者を量子アルゴリズムで改良する。後者は、古典計算機のマシンパワーを活用する。その意味では、ハイブリッド法である。
1⃣ 最小値探索ステップ
最適化≃最小値探索であり、量子的手法を使った最適化手法の代表例は、変分法もしくは量子アニーリング法であろうが、本論文では、グローバー・アルゴリズムを使う。それは、フィボナッチヒープ優先キューを利用したダイクストラ法が、絶妙なソートを行って計算コストを激減させているからである。量子版は、ソートを行わないこと(構造化されていないリストにおける最小値探索)に光明を見出した。それは、問題サイズが小さい場合は、ソートしない方が実用的な場合もある、ことを根拠にしている。
[グローバー・アルゴリズム]
グローバー・アルゴリズムは、古典アルゴリズムよりも高速であることが数学的に証明されている。ただし、2次加速である。2次加速する量子アルゴリズムは、珍しくない。2次加速は、「量子系で確率を得るためには、確率振幅を2乗しなければならない」という事実に由来するらしい[*43]。指数加速を実現する(と喧伝される)ショアのアルゴリズムは、皮肉にも、より高速な古典アルゴリズムが存在しないという証明が数学的になされていない。それは、ともかく、グローバー・アルゴリズムは問題サイズが大きいと、古典アルゴリズムとの差が大きくなる。この事実も、本論文の結果を混乱させる(が、誤植ではない)。
2⃣ 更新ステップ
ダイクストラ法の更新ステップとは、優先順位キューQにおける重みの更新である。このステップにかかる時間を、量子改良アルゴリズムでは、(NVIDIA Tesla V100?)GPUを使った並列化で短縮させる。有向非巡回グラフ(DAG)が疎である(各頂点の隣接頂点数が比較的少ない)という性質から、効率的に並列計算が可能、という。
【3】セットアップ及び成果
(1) 量子的セットアップ
❶ 量子モダリティは、超伝導、トラップイオン、中性原子の3種類である。3種類の量子ゲート(Xゲート、Hゲート及びCNOTゲート)が動作に要した平均時間(ミリ秒)、及びZ測定に要する平均時間(ミリ秒)を比較して、超伝導方式がダントツに速かったため、本論文では、モダリティとして超伝導を選択している。
❷ 具体的には、IBMの量子シミュレータ(QASM Simulator)と、超伝導方式の量子ハードウェア(Quito)を採用している。また、誤り緩和ソフトとして、豪Q-CTRLのFire Opalを使用する。量子シミュレータは、密度行列シミュレータを使用している。その理由は、(純粋状態のシミュレーションに限定される状態ベクトルシミュレータと異なり)密度行列シミュレータは、混合状態を扱うことができ、様々なノイズ源を考慮することができるため、柔軟性が高い、からと説明されている。
Fire Opalは、「パルス制御等を通じて量子プロセッサを、AIで調整することで、ノイズやデコヒーレンスを極小化し、自律的な誤り抑制を実行する」とされている。Q-CTRLは、計算コストが100倍削減されると主張している。なお、22年12月から、クラウド経由で、Fire Opalは無料提供されている。
(2) その他セットアップ
❶ 有向非巡回グラフ(つまり、飛行経路のネットワーク)は、(パイソンのライブラリー)NetworkXライブラリを使用して作成されるている。なお、この 有向非巡回グラフは、元の経路と複数の摂動経路の両方を包含している。
❷ ちなみに、航空機はエアバスA320 が選択されている。エンジンは、CFM International(GEアビエーションと仏スネクマのJV)の CFM56-5B4が選択されている。
❸ ウェイポイント=2N、N=量子ビットの数である。ウェイポイントの設定数は、以下の通り:短距離の国内線で平均12。長距離の国内線で平均25。国際線で平均50。国際線で言うと、ニューヨーク・ロンドン/パリ・北京/ムンバイ・シドニーといったように、各ケースごと、3つの路線が設定されている。
(3) 古典と量子アルゴリズムの比較方法
古典アルゴリズム(ダイクストラ法)と、量子アルゴリズム(Groverアルゴリズムを利用した最小値探索アルゴリズム)のそれぞれが、最適経路を見つける時間を比較する。
量子アルゴリズムは、各種量子ゲートの数に、対応するゲートの動作時間を掛け合わせて、計算している。具体的には、まず、❶最小値探索アルゴリズムの動作を、量子ゲート(X、Y、Z、S、H、Tゲート。CNOTゲート、SWAPゲート)の動作、|+〉と|0〉の状態準備、X測定、Z測定に置換した。次に、❷「ゲート数、状態準備の数、測定の数」に、 それぞれの要する時間をかけて、量子アルゴリズムが、最適経路を見つける時間を算出した。
(4) 結果
❶ どちらが速いか
N=2~4(つまりウェイポイント4~16)では、量子アルゴリズムが、わずかに速い。N=5及び6(ウェイポイント32及び64)では、量子アルゴリズムと古典アルゴリズムの差が、広がる。N=7(128)で、差がなくなり、N=8(256)では、古典アルゴリズムが速い。
この奇妙な結果については、【4】考察(1)を参照。
❷ 忠実度
量子コンピュータで得られた結果の忠実度は、シミュレータから得られた結果に比べて、かなり低い、と判断している。そして、「Fire Opal(のような量子誤り緩和ソフト)を利用することで、忠実度を高めることは可能」だが、「回路を再コンパイルする必要があるため、オーバーヘッドが発生する」ため、「緩和ソフトを、よりシームレスに統合することが期待される」、と結んでいる。
(5) 提案
ちなみに、本論文では、次のような提案を行っている。
❶ プリコンパイル
現在のアーキテクチャでは、ネットワークコストとパイソンによる量子回路の構築に大きな時間的コストがかかっている。例えばグローバー・アルゴリズムで、4量子ビットの回路を組み立てるには124ミリ秒が必要であり、回路構築を効率化するさらなる工夫が必要である。その一つが、振幅増幅回路に、コンパイル済みの回路を使用する方法である。
❷ 並列化
測定や量子ビットのリセットに時間がかかることから、並列化は重要な技術になる可能性がある。さらに、振幅増幅アルゴリズムの実行時間は、より大規模な量子デバイス上で回路を並列化することで短縮できる可能性がある。
【4】考察
(1) (本論文における)量子改良アルゴリズムが奇妙である構造の考察
❶ 量子コンピュータの高速化が漸近的であることは、広くコンセンサスを得ていると思われる。つまり、問題のサイズが大きい(本論文の場合は、ウェイポイントが多い)場合は、量子コンピュータが高速である、というのがコンセンサスである。このステートメントは、コンピュータ→アルゴリズムと置き換えても、それほどの混乱は生じないだろう。それよりも、問題サイズが小さいと量子アルゴリズムが速い、という本論文の結果が混乱を生じさせる。ただし、これは、つぎのような説明で納得できるだろう。
まず古典アルゴリズム(フィボナッチヒープ優先キューを利用したダイクストラ法)が滅茶苦茶速いから、同じ土俵では勝てない。そこで、ソートをしない方が有利な、問題サイズが小さい領域で勝負をする。幸いなことに(予定調和の匂いがするものの)、問題サイズが小さい領域は、現場の問題解決にとって現実的なサイズであった。この時点で、古典アルゴリズムを「探索と更新」に2分割して、局地戦での個別勝利を目指している。
そして、探索戦では、ソートなし状態で探索が速いという特徴を持つ量子アルゴリズム「グローバー・アルゴリズム」を、引っ張り出してきた。更新戦では、GPUをフル活用して、時短を達成した。
驚くべきは、ここまで形振構わずに、総力戦を仕掛けても古典アルゴリズムに辛勝したに過ぎないという事実であろう。
❷ 少し補足
グローバー・アルゴリズムは問題サイズが大きい領域で古典アルゴリズムとの差が大きくなるが、本論文の結論は、問題サイズが小さい領域で量子アルゴリズムが速いと主張する。その点が、(余計に)混乱を生じさせるかもしれない。しかし、先の議論は、データをソートしていない場合の議論である。本論文では、絶妙にソートしたデータに古典アルゴリズムを適用したケースと、ソートしていないデータにグローバー・アルゴリズムを適用したケースを比較しているから、矛盾は生じない(と理解している。量子テレポーテーションが特殊相対論に矛盾していないことと、同じ(?)腹落ち感がある)。
❸ 少し定量的な考察
フィボナッチ・ヒープ優先キューを使用したダイクストラ法の計算コストは、O(E+V log V)であった。一方、量子改良アルゴリズムは、O(L*V√V)である。ここでLは、「GPUによる並列化で、更新ステップの計算量が削減された割合」を表す(つまり1-Lが、削減割合)。非常に荒っぽくE≃Vとおいた上で、Lをパラメータと考えて振ってみた結果と本論文の実験結果を見比べると、L=0.52~0.55(つまり更新ステップの計算量は、並列化でほぼ半減した)で整合すると思われる。
(2) 単なる感想
あまり、意味はないが、古典アルゴリズムとして、シミュレーテッド・アニーリング法を採用して、量子アルゴリズムとして量子アニーリング法を採用すると、どういう結果になるのだろう?
ちなみに、ウルグアイのQuantum-Southというスタートアップが、量子アニーラを使って、航空機でのコンテナ(ULD)負荷の最適化とULDのビンパッキング最適化を行っている。
【0】はじめに
機械学習も”量子化”することで、古典的機械学習に比べて、性能を上げられる=「古典越え」・・・を期待することは、自然であろう。なお、ここで言う量子化とは、深層学習の文脈で、「枝刈り」や「蒸留」と同列に現れる量子化とは異なる。さて、量子化という言葉で期待される高性能とは、一般に、高速ということであろう。一方で、機械学習における高性能とは、(分類タスクにしろ、回帰タスクにしろ)精度が高いことを意味するだろう。
量子機械学習の分野における「古典越え」は、まず『(1)古典的機械学習と同じ精度に達するまでの時間が短い』という主張から始まった(と思われる)[*44]。次に『(2)データが少なくても、古典的機械学習と同じ精度に到達可能』との主張が行われ、さらに『(3)(ユースケースを特定して)量子機械学習の精度が、古典的機械学習よりも高い』という主張が行われるようになった(と思われる)。
独ミュンヘン大学(ルートヴィヒ・マクシミリアン大学ミュンヘン)の研究者他は、上記(3)を主張する論文(以下、本論文[*45])をarXivにて公開した(23年6月8日)。
【1】本論文の主張
「学習データにノイズが多く含まれており、学習データの量が少ない」場合に、量子ニューラルネットワーク(QNN)は古典的(人工)ニューラルネットワークよりも、精度が高い、と主張する。ここで言うQNNは、(パラメータ付き)量子回路で構成されたニューラルネットワークを意味する。
【2】事前整理
(0) 本論文で想定されているユースケース
まず、本論文が想定しているユースケースを明示する。それは、ニューラルネットワークを代理モデルとして使用する化学や医薬品の開発である。より直截的に言うと、ブラックボックス関数最適化問題である(詳細は後述)。
本論文は、以下のように述べる:化学や医薬品の開発現場(に限定されないものの、そこ)で実施される実験には、①実験のセットアップの不正確さ、②読み出しエラー、その他タイプのノイズなど、Aleatoric不確実性(環境自身の不確かさで、学習しても改善しない不確実性)がつきまとう。
また、デジタル領域(におけるニューラルネットワークを使った学習)と比べて、材料や医薬品の開発におけるデータ量は少ない[*46]。その理由としては、「コストや時間の関係上、実験回数が限られる・データ取得コストが高い。データが紙で管理されている。データが属人的に管理されている」等が上げられている。理由はともかく、ノイズが多い・データ不足という状態で発生する問題とは、過学習である。QNNは、そのような状態に対して堅牢であるとされており、本論文もその主張に沿っている。
(1) ブラックボックス関数最適化問題
ブラックボックス関数最適化問題(BBO)は、(最適化問題における)目的関数が不明であるため、ブラックボックスという枕詞がついている。目的関数の姿が不明なので、目的関数の解析的情報を使用する最適化アルゴリズムは使えない。化学や医薬品の開発現場では、コスパやタイパが良い実験を計画・設計するというような場面で、BBOが登場する。材料開発の文脈では、材料の作製条件の同定、物性パラメータの同定、といった場面で登場する。機械学習の文脈では、ハイパーパラメータのチューニングといった場面で登場する。BBOの代表例としては、(逐次近似最適化手法の一つである)ベイズ最適化がある。(本論文で、ベイズ最適化を採用しているという記述はないが、そういう理解で大きな問題はないと思われる。)
(2) データが不足している場合の、そもそも論
機械学習でデータが不足している”一般的な場合”には、データ拡張、転移学習、連合学習といった対処法が採られる。ベイズ最適化は、その方向のアプローチとは異なる。そもそも論としてベイズ最適化は、少ないデータ(試行)から、最適な条件やパラメータを探索するという思想の下で構築された方法論である。これと似たようなアプローチとして、能動学習・不確実性サンプリングがある。こちらは、少数の学習データから”良い”モデルを学習するための方法論である。
ベイズ最適化(を含む逐次近似最適化手法)では、不明な目的関数の代わりとなる「代理関数」の概形を求めながら、その最適値を、逐次的に求める。ベイズ最適化では、❶「代理関数の平均と分散を、ガウス過程からサンプルして、代理関数を生成するとともに、最適値を探索する」、というアプローチが採用されることが多い。ガウス過程以外にも、❷ランダムフォレストを使って、あるいは❸ニューラルネットワークを使って、代理関数と最適値を探索する、というアプローチもある。本論文は、❸に該当する。
ちなみに、ガウス過程を使ったベイズ最適化は、ノイズの含まれるデータに対して、堅牢であるとみなされている。
(3) 最適化アルゴリズム向けベンチマーク関数
最適化アルゴリズムの評価法として、ベンチマーク関数と呼ばれる評価関数にアルゴリズムを適用し、最適解を探索させる、という手法が一般に採られる。本論文では、以下の3つのベンチマーク関数を採用している。
㊀Griewank関数・・・大域的には単峰性関数のような性質を持つが、局所的には多数の局所的最適解が存在する多峰性関数。
㊁Schwefel関数・・・最適解を探索領域の境界付近に持つ多峰性関数。
㊂Styblinski-Tang関数・・・大域的最適解の周辺に多数の局所解を持つ多峰性関数。
【3】セットアップ
(1) データ
1⃣ ノイズありデータ
ノイズに対してQNNは堅牢であることを実証するため、ノイズありデータを作成し、ノイズありデータでも学習させている。ノイズありデータは、ベンチマーク関数の値f(xi)に白色雑音zを加えて作成している。正確に言うと、ノイズ係数をδとして、f(xi)→f(xi)+δzとする。δは、0.1刻みで、0.1~0.5であり、z~exp(-z2/2)/√2πである。サンプルサイズは「10,20,30,40,50」である。なお、「100,400,900,1600,2500」というデータサンプルの範囲に対して、ノイズを加えている。
なお、ノイズありデータの場合、ベンチマーク関数は、Griewank関数のみである。その理由として、「Griewank関数に適した量子代理モデルを見つけるために必要な層の数と、計算量は、他の関数よりもはるかに少ない」ことをあげている。
2⃣ ノイズなしデータ
ノイズがない場合は、先の㊀~㊂全てを使用している。さらに、ノイズがないデータとしては、「色度測定に関連する化学プロセスから得られた241の6次元データポイントを含む、実世界のデータセットColor bob」も使用されている。
(2) 古典ニューラルネットワーク
❶オプティマイザー・・・Adam
❷構成・・・入力層+隠れ層(2層)+出力層。第1隠れ層は10個のニューロン、第2隠れ層は3個のニューロンで構成。
❸活性化関数・・・第1隠れ層は、シグモイド関数。第2隠れ層は、tanh関数。
❹その他・・・ハイパーパラメータ・チューニングなし。正則化なし。
(3) 量子ニューラルネットワーク(QNN)
❶符号化・・・角度符号化を採用。その理由として、「NISQハードウェアで実行する場合、不完全なゲート忠実度に対して、より堅牢な回路を実現することができる」をあげている。
❷オプティマイザー・・・IBMが作った量子コンピュータ用SDK「Qiskit」のCOBYLA(Constrained Optimization By Linear Approximation optimizer)を選択している。その理由として、「ノイズのない目的関数の評価数を最小化するため、特に効率的である」をあげている。
❸測定演算子・・・計算基底での測定(パウリZ測定)
❹構成・・・データ符号化層とパラメータ化層でミニマムセットを構成。データ符号化層は、データの再ロードを行い、入力データ1点につき2量子ビットを使用することで並列符号化を行う。パラメータ化層は、アラン・アスプル=グジック他による文献[*47]から採用した、2種類のパラメータ化された量子回路(いわゆるansatzアンザッツ)、量子回路1と量子回路2を組み合わせている。2種類を組み合わせた理由として、「データの再アップロードや並列符号化が生み出す非線形成分のスペクトルを十分に活用するためには、回路全体の符号化された量子ビット数の少なくとも2倍のパラメータが必要である」をあげている。
なお、量子回路1は「1量子ゲート(パラメータ付き回転ゲート)+CNOTゲート」で構成されており、量子回路2は「パラメータ付き回転ゲート+アダマールゲート+CZゲート」という構成である。CNOTゲート、アダマールゲート、CZゲートが重ね合わせと量子もつれを作り出す。
量子回路1と量子回路2は、表現力ともつれ能力のバランスで選ばれたことになっている(詳細については【参考2】を参照)。
【4】結果
(1) 評価指標
R2スコアを採用。モデルが結果を完全に予測する場合にR2スコアは1となり、結果の予測精度が低くなるようにつれて、0に向かう。また、QNNと古典NNの比較では、QNNのR2スコアから古典のR2スコアを減算した数値「デルタR2」を、評価指標として用いる。
(2) 結果
QNNは、量子回路シミュレータで実行されている、ことに注意。現在の量子回路シミュレータでは、48量子ビットまでの小さな回路をシミュレートできることが示されている、らしい。その一方で、8量子ビットまでしか、合理的に速く動作することができない。ここで、合理的に速くとは、2時間以内、という意味である。
❶ ノイズがない場合の結果・・・ 本論文で提示されたQNNモデルが、与えられた関数をうまく表現できるかを検証することが、ノイズなしデータでの検証の役目である。QNNは、Griewank関数では20層・3000回の計算で、Schwefel関数とStyblinski-Tang関数では42層・4000回の計算で、R2スコア0.94を達成した。Color bobデータセットでは、データ符号化層と回路1=「1量子ゲート(パラメータ付き回転ゲート)+CNOTゲート」のセットからなる3層で、最適化を500回繰り返すだけで、0.9に近いR2スコアを得ることができた。
この結果から、QNNモデルは、与えられた関数にうまく適合できた、と結論付けている。
❷ ノイズがある場合の結果・・・本論文では、「サンプルサイズを小さくし、ノイズレベルを上げると、相対的にQNNの精度が向上する」と主張し、このことをもってQNNの汎化能力がより優れている、と結論している。
確かに、ノイズレベルに関しては定性的な結果(全体的な傾向)が得られている。ノイズレベル0.3以上だと量子>古典であり、0.3未満だと古典>量子である。ただ、サンプルサイズに関しては、明確な全体的傾向は現れていない(つまり、サンプルサイズが小さければ量子>古典、というような定性的な結果は見られない)と思われる。
【参考1】 量子コンピュータでのテスト結果
IBMの実機(NISQマシンIBMq belem、5量子ビット)でも、QNNを実行している。その結果はと言うと、現在の”高い”誤り率により、「2次元の入力データに対して、1次元あたり2量子ビットを使用した場合、最終的に常に失敗した」。3量子ビット、6層、100回の繰り返しで、1次元のGriewank関数をなんとか表現することができたものの、R2スコアは0.54に過ぎなかった。
よりバージョンアップしたFalcon r5.11(ただし、Falconファミリーの最上位機種は21年9月にリリースしたr8)でも、次元のGriewank関数を十分にモデル化することはできない。
【5】考察
まとめると、例えユースケースを絞ったとしても、「ニューラルネットワークで、量子>古典を主張することは難しい」かつ「実装を想定すると、さらに難しい」ということになるだろうか。
(1) サンプルサイズが小さければ量子>古典、というような定性的な結果は見られない、という根拠を以下に示す:サンプルサイズを行、ノイズレベルを列、とみなしてデルタR2の値を並べた”行列”(本論文では図3が該当する)の各成分で「等高線」を作る。列方向=ノイズレベルでは88%の確からしさで量子>古典を支持する。一方、行方向=サンプルサイズでは28%の確からしさでしか、量子>古典を支持しない。
ただし、「サンプルサイズ小×ノイズレベル大」の行列成分で、局所的に(本論文では、「相対的に」)QNNの精度が向上しているという解釈は、可能であろう。
(2) ノイズレベルに関しても、計算コストの問題があるにせよ、ベンチマーク関数1種類で、量子>古典を明言するのは、難しいと感じる。さらに、(ノイズレベルに関して)得られた結果は、定性的な結果であり、定量的な結果ではない。このため、実装を考えるとQNNに切り替える、という話にはならないと思われる。
(3) また、古典ニューラルネットワークをチューニング(ハイパーパラメータ・チューニング、正則化)する等で、今回のQNNの結果を超えることは(おそらく)可能と思われる。そういう手間なしで、QNNは高い精度が出せるという主張だろうが、現場はその手間をかけてでも、良い結果を求めて古典アルゴリズムを改良していると考えられる(あるいは、AutoMLでハイパーパラメータ・チューニング等が自動化できれば、手間は要らない)。
(4) なお、QNNを構成する量子回路1は、[*47]において妥当な回路コストを維持しながら、高い表現能力を有する、と評価されている。量子回路2は、もつれ能力に関して高い評価が与えられている。詳細は、【参考2】を参照。
【参考2】 量子回路の選択
[*47]は、次の問いに対する答えを探索した論文である:2 つのパラメータ化量子回路(POCあるいは、アンザッツansatzと呼ばれる) A と B がある場合、特定のアプリケーションには、どちらの回路がより適しているか? またその理由は何か?
答えとして、[*47]は、(古典的シミュレーションを使用して)アンザッツを特徴付け・評価するための一連の操作記述子を提示している。その記述子とは、表現可能性ともつれ能力である。表現可能性は、「ヒルベルト空間を、上手に(英語ではwell)表現する純粋状態(→密度演算子)を、生成する回路の能力」と定義されている。例として、1量子ビット(アンザッツ)の表現可能性は、「ブロッホ球を探索する回路の能力」に相当する、と書かれている。アンザッツのパラメータは、1量子ビット回転ゲートの角度である(ことがほとんどである)から、実質的に「アンザッツの表現可能性=ブロッホ球を探索する(アンザッツの)能力」と見做して良いだろう。
もつれ能力は、「深度の低い回路で、高度にもつれた状態を生成する能力」と定義されている。もつれ能力の潜在的な利点として、「基底状態の準備やデータ分類などのタスクの解空間を、効率的に表現できること」および「量子データ内の非自明な相関を捕捉できること」をあげている。このため、変分量子固有値ソルバー(VQE)や量子機械学習で、重要な能力であるとしている。
[*47]は、これまで知られている19のアンザッツを対象にして、表現可能性ともつれ能力を評価している。まず、表現可能性について、(本論文では量子回路1である)回路11は(回路12、19とともに)、より単純な回路接続(つまり妥当な回路コスト)で、高い表現可能性を実現する、という評価を与えられている。一方、もつれ能力に関しては、回路11に関する記述はない。
もつれ能力に関しては、(本論文では量子回路2である)回路 9 は高いもつれ状態を出力することができる、と評価されている。その一方で、表現可能性は(1層の場合)、19個のアンザッツの中で最も低い。ただし、層を2層にすることで、表現可能性は60%以上増加する。3層にすると、さらに60%以上増加する。ただし、その場合、高いもつれ状態を出力することはできない。
結論としては、回路11と回路9の組み合わせは、高い表現可能性と高いもつれ能力を併せ持つ(アンザッツを使った量子機械学習にとって優秀な)、組み合わせと言えるだろう。
=>表現力の高いアンザッツは、精度を抑制するという研究結果もある[*51]ので、必ずしも優秀な組み合わせではないかもしれない。
【参考3】 データが不足している場合の対処法
1⃣ データ拡張(Data Augmentation)
データの拡張は、画像データに限定されない。自然言語処理や金融分野[*48]における機械学習でも現れる。ただし、その出自から、画像データを基に語られることが多い。曰く、「既存のデータセットを、変形させて新たなデータを生成する手法である」というような説明がなされる。この場合の変形とは、回転、平行移動、水平反転、色の変更などを指す。変形操作を画像データに対してランダムに適用することで、新たな画像データを生成する。
不均衡データにおけるオーバーサンプリングも、データ拡張 に該当するとしても良いだろう。不均衡データとは、クラス間で事例の数や割合が極端に異なるデータを言う。金融であれば、堕天使(債券が投資適格から非適格に堕ちること)やデフォルト、クレジットカードの不正使用あるいはマネーロンダリング取引では、不均衡データに遭遇する。医療診断やサイバー攻撃でも、不均衡データに遭遇する。
画僧データ以外では過学習の問題が、指摘される。
2⃣ 転移学習(Transfer Learning)
転移学習とは、別タスクによって学習済みのモデルを、(しばしば下流タスクと呼ばれる)目的タスク 用のデータセットで再学習(ファイン・チューニング)する学習方式である。学習済みモデルは大規模なデータセットで事前学習されているため、再学習では、少量データで目的タスクを学習できるとされている[*52]。過学習の問題はつきまとうが、学習率を小さくして、回避するといった方法がとられるようである。
転移学習では当然、事前学習済みモデルが前提となる。大きな社会実装を意識すると、事前学習済みモデルは、「基盤モデル」という文言をあてて呼ばれる。基盤モデルという言葉自体は、スタンフォード大学によって広められたとされている。オープンAIのGPT(チャットGPTも含まれる)は、基盤モデルと呼べるだろう。ただし、GPTは再学習ではなく、fewーshot学習を採用している。
3⃣ アンサンブル学習(Ensemble Learning)
アンサンブル学習は、複数の学習モデルを組み合わせて予測を行う手法である。データ量が不足している場合でも、異なるモデルを学習させ、それらの予測結果を統合することで、より高い精度を得ることができる、とされる。一般に、過学習を起こしにくいとされている。
4⃣ 連合学習(Federated Learning)
一見違ったアプローチとして、2017年にグーグルが提唱した、連合学習がある。ただし、データは集約しない。分散しているデータを分散したままマージして、学習を行う。データが足りなければ(どこかにはあるので)、集めて増やせば良いという発想である。学習モデルという観点からは、「アンサンブル学習と事前学習済モデルの組み合わせ」という見方もできる。
実際の取り組みとして、金融分野(クレジットカードの不正使用対策)では、情報通信研究機構による「プライバシー保護連合学習技術を活用した銀行の不正送金検知の実証実験」がある。検知精度80%以上を達成し、不正口座として凍結されるよりも大幅に速く検知できた、という[*49]。
創薬の分野では、 2019 年から開始された欧州のMachine Learning Ledger Orchestration for Drug Discovery (MELLODDY) コンソーシアムが有名である。データの秘匿性を保持しながら 1,000 万を超える低分子化合物のデータを共同利用できる枠組みを活用して、有望な医薬品候補物質の予測プラットフォームを構築することを目指している[*61]。日本では、AMED創薬支援推進事業「産学連携による次世代創薬AI開発」がある。化合物―生体分子親和性予測AI、化合物構造発生AI及びオミクス情報に基づく標的予測AIの開発を目的としている[*50]。
連合学習の課題としては、「通信コストが高い、計算時間が長い、プライバシーの懸念」等が上げられている。
【0】はじめに
米Quantinuum(クオンティニュアム、以下、該社とも表記する)の研究者は、量子位相推定法(QPE)を適用した量子化学計算をNISQマシンで実行した、という論文[*53](以下、本論文。arXivにて23年6月30日公開)を発表した(アナウンスは7月10日[*54])。該社によると、論理量子ビットを用いたQPEを、量子化学の問題に適用したのは世界初(該社調べ)。実行された量子化学計算を具体的に言うと、水素分子の基底状態のエネルギー計算である。なお、本論文の筆頭著者は、日本人(山本憲太郎博士)。
【1】本論文の新規性
QPEをNISQマシンで実行できたカラクリは、❶ベイジアン量子位相推定法の採用と、❷独自の量子誤り検出符号の採用による。❶は、該社独自のアイデアではないが、以下1⃣~3⃣に示すように工夫を凝らしている。一方、❷=4⃣は、該社独自のアイデアである。なお3⃣と4⃣は同時には適用されない。つまり、3⃣を単独で使う、若しくは4⃣を単独で使う。
本節では、新規性について、頭出しのみを行う。詳細は【3】を参照。
1⃣ 先行研究では、ベイズ推定で使用する事後分布のパラメータを、決定する方法が示されていなかった(パラメータ選択が、最適化されていなかったという問題意識)。ヒューリスティックを使用したり、ランダム・サンプリングに頼っていた。
2⃣ 適応型ベイジアン量子位相推定法において、フーリエ分布からの切り替え先を「くるまれたガウス分布」ではなく、フォン・ミーゼス分布としている。
3⃣ 先行研究では、量子計算でノイズが発生しないと仮定している。これは非現実的なので、本論文では、(ベイズ推定に不可欠な)尤度関数にノイズを考慮している。具体的には、量子デバイスの仕様及び深さパラメータの関数として決定される、デコヒーレンスによる誤差パラメータqを考慮した。
4⃣ 該社の量子コンピュータ用に開発された量子誤り検出符号で実現された、論理量子ビットを作成・使用した。
【2】事前整理
(0) 量子位相推定
基底状態とその固有値(基底状態のエネルギー)を求めるアルゴリズムとしては、VQE(実は、定まった和名はない。代表的には「変分量子固有値ソルバー」と呼ばれる)が広く知られている(励起状態を、基底状態から逐次的に求める「工夫」もあるにはある)。VQEは、NISQマシンを前提とした量子古典ハイブリッドアルゴリズムであり、その名の通り、変分法をベースとしている。NISQ×VQE≒古典コンピュータ×古典アルゴリズムという意見は、珍しくない(例えば、[*55]や[*56]。論点も同じ)。
(励起状態を含めた)固有状態とその固有値(エネルギー)を求めるアルゴリズムとして、量子位相推定法(Quantum Phase Estimation:QPE)がある。QPEでエネルギーを求めるロジックは、次のようなものであった[*55]:重ね合わせ状態の量子ビットに、時間に依存しないハミルトニアン(=エネルギー)から作られるユニタリ時間発展演算子を作用させて『制御・時間発展』させる。そうすると、時間発展前の量子ビットと、時間発展後の量子ビットが得られる。それぞれの量子ビットの位相を、逆量子フーリエ変換を使って抽出する。最後に、位相差から、エネルギーを計算する。補足的に言葉を繋ぐと、以下のようになる:ユニタリ時間発展演算子に固有ベクトルと関連する、位相を顕わにした固有値を与えて、位相の推定値を計算する。故に、位相差からエネルギーを求めることができる。
QPEは、固有値を求める古典アルゴリズムに対して指数関数的に高速であることが、数学的に証明されている。正確に言うと、波動関数の時間発展並びに量子逆フーリエ変換は、量子誤り訂正機能を備えた量子コンピュータ「誤り耐性量子コンピュータFTQC」では、分子サイズに対して多項式時間で実行できる。
量子逆フーリエ変換においては、多数のゲート操作が必要となる。多数のゲート操作は(ゲート操作の忠実度が100%でない以上)、量子誤りの蓄積を惹起する。蓄積した誤りは、訂正しない限り、量子計算は破綻するから、量子誤り訂正が必要となる。要するに、量子逆フーリエ変換を必要とするQPEは、FTQCでなければ実行不可能と考えられていた。
(1) ベイジアン量子位相推定法
本論文によれば、QPEにおける(一つの大きな)改良は、(量子情報理論の世界で超有名な)キタエフによる反復スキーム(iterative scheme,1995!→2008にリバイスされている)から始まっている。このスキームについて「量子フーリエ変換に基づく QPE と比較して、より多くのサンプルを犠牲にして”浅い回路を使用する”ため、ノイズの多い量子ハードウェアでの実行が容易になる」と記述している。
反復量子位相推定法の一つに、ベイジアン量子位相推定法(以下、B-QPE)がある。B-QPE は、位相推定プロトコルをより効率的かつ実験誤差に対して堅牢にするための、ベイズ推定に基づくアプローチである。B-QPEは(正確には、B-QPEに限らず、反復QPEは)量子フーリエ変換・逆量子フーリエ変換を使わない。(B-QPEでは)代わりに、ベイズ推定を利用する。量子逆フーリエ変換を用いないので、ゲート操作が減り、NISQでも可能という理屈である。
B-QPEを提唱した論文[*57]によると、B-QPEは「実装容易で、(推定誤差は)ハイゼンベルク限界を達成し、脱分極ノイズに耐性があり、FPGA上で実行でき」、「キタエフの方法などの、既存の反復位相推定アルゴリズムよりも優れている」。
本論文は、 量子CCD(電荷結合デバイス)トラップイオン量子コンピュータ上で、”適応型”B-QPEを実行し、水素系の基底状態エネルギーを計算している。
(2) ベイジアン量子位相推定法(B-QPE)でエネルギーを求めるロジック[*55]
B-QPEでエネルギーを求めるロジックは、QPEとは(全く)異なる。QPE量子回路に、わざわざ、制御された回転ゲートを追加する。そうすることで、制御・時間発展させて得られる「時間発展前の量子ビット」と「時間発展後の量子ビット」にパラメータを導入することができる。このパラメータを工夫すると(例えば、εtと置くと)、求めたいエネルギーEにパラメータεを導入することができる。直截的に言えば、E→Eーεという形にできる。そして、なんと「時間発展前の量子ビット」の確率振幅は、 E=εで1になり、「時間発展後の量子ビット」の確率振幅は、 E=εで0になる。
つまり、「時間発展前の量子ビット」が測定される確率が1になるように、パラメータεを調整すれば、そのときのεは求めたいエネルギーEに等しい。実際のところ、確率1は難しいので、現実的には、「時間発展前の量子ビット」が測定される確率を最大にするというタスクになる。「時間発展前の量子ビット」が測定される確率を最大にしたときのεは、Eの良い近似になっている、と考えられる(若しくは、考える)。ベイズ推定を用いてパラメータ推定を行うので、 ベイジアン量子位相推定法という名前になっている(と思われる)。
時間発展させたはずなのに、「時間発展前の量子ビット」が測定される確率が1というのは奇妙である。それは(わざわざ追加した)制御された回転ゲートが、”時間反転術式”を使って時間発展を中和したと考えれば、納得できるだろう。量子系では、時間反転対称性が破れていないと考えられるので、理論上問題ないのだろう。
(3) 適応型ベイジアン量子位相推定法
B-QPEはベイズ推定に基づくアプローチであるから、測定結果に基づいて事後分布を更新する。位相は、事後分布を通じて確率的に定量化する。一般的な適応型B-QPEでは、メモリ要件を軽減するために、事後分布は、事後分布の更新数が適当なところで、フーリエ分布から「くるまれた(英語では、wrapped)ガウス分布」に切り替わる。「くるまれたガウス分布」とは、無限長の区間を持つガウス分布に従う確率変数を、主値域にくるんだ確率分布である。すなわち、主値域幅で切り刻み、主値域に重ね足し合わせた確率分布である[*58]。「くるまれたガウス分布」は(も)、平均と分散で完全に表現可能である。本論文によれば、フーリエ分布から「くるまれたガウス分布」への変換は近似値だが、十分な更新数の後、事後分布はピークに達し、フーリエ分布は「くるまれたガウス分布」によってよく近似される。
ただし本論文では「くるまれたガウス分布」の代わりに、(代表的な、単位円周上の確率モデルである)フォン・ミーゼス分布を使っている。つまり、 事後分布の更新数が適当なところで、フーリエ分布からフォン・ミーゼス分布に切り替わる。その理由として、「フォン・ミーゼス分布が、くるまれたランダム変数の最大エントロピー分布であり、単純な確率密度関数の閉形式を持っているため」としている。また、くるまれたガウス分布と同様に、「フォン・ミーゼス分布も平均値と精度パラメーターによって完全に表現され、モーメント・マッチングを使用して、分析的に更新することも可能」であることも、上げられている。
(4)〚n + 2, n, 2〛量子誤り検出符号
量子誤り検出符号による誤り率の抑制は、シンドローム測定によって検出された、誤った計算を破棄するという犠牲によって、達成されている。別の表現を使えば、量子誤り検出符号は、そういう思想の下で設計されている。〚n + 2, n, 2〛符号(nは偶数)[*59]は、符号空間が X⊗n+2および Z⊗n+2によって安定化される、スタビライザー符号である。この誤り検出符号は、任意の1量子ビットエラーを検出し、関連する結果を破棄することで、回路の深さと幅におけるオーバーヘッドを小さくして、誤り率を削減する。本論文ではn = 4 、つまり〚6、4、2〛コードを使用して、4 つの論理量子ビットを符号化する。
【3】新規アイデアの詳述
(1) パラメータの決定
本論文は、シミュレーションを行った結果を示して「最適なパラメータ選択により、ベイジアン位相推定の精度が大幅に向上した」、と主張している。以下、その中身を書き下してみる。
ベイジアンQPEは、ベイズ推定の枠組みを採用しているので、事後分布が、尤度関数×事前分布に従って、必要な精度が得られるまで更新される。尤度関数は、3つのパラメータ(φ、k、β:φは、QPEで推定する位相)の下で、量子ビットの測定結果mが得られる”可能性”を表す。m∈{0, 1} である。決定するパラメータとは、尤度関数のパラメータ(kとβ)である。
kとβは、効用関数を最大化するという条件で決定する。事後分布が必要な精度まで更新されたかは、事後分布の分散を評価することによって判断できるから、効用関数は分散を使って表現される。しかし、くるまれた分布と標準的な(つまり正規分布の)分散は、相性が悪い。そこで、別の分散が使用される。本論文では、サーキュラー分散とホレボ分散を候補として上げ、最終的にはサーキュラー分散を採用している(フーリエ分布とフォン・ミーゼス分布ともに、サーキュラー分散とホレボ分散は、解析的であると言及されている)。
パラメータ決定に関するシミュレーションは次の3パターンに対して、ノイズなしを仮定しており、100 の異なる真の位相 にわたって行われた。アウトプットは、「真の位相とのコサイン類似度の期待値」である。
❶ 事後分布=フォン・ミーゼス分布、パラメータはヒューリスティクスでセット。
❷ 事後分布=フーリエ分布、パラメータはヒューリスティクスでセット。
❸ 事後分布=フーリエ分布からフォン・ミーゼス分布に切り替え、パラメータは上記方法で決定。フーリエ係数の数が2000 を超えるとフォン・ミーゼス分布に切り替える。
結果は非常に明白である。 ❸は 「真の位相とのコサイン類似度の期待値」の平均値で、10-5程度を叩き出している。❶は0.1、❷は0.01程度である。つまり、「最適なパラメータ選択により、ベイジアン位相推定の精度が大幅に向上した」ことになる。
(2) ノイズの考慮
誤差パラメータqを、具体的に書き下す。まず、①脱分極ノイズを仮定する。次に、②回路内の2量子ビット ゲートの数NTQ を深さパラメータとして、q=1-(1-p2)NTQと提案している。ここで、p2は、脱分極エラー率である。
(3)〚6、4、2〛量子誤り検出符号
〚6、4、2〛量子誤り検出符号 は、以下のように構成される。1つのダミー量子ビットが追加されたQPE回路は、論理量子ビット×4+冗長物理量子ビット×2=6物理量子ビット、でエンコードされる。さらに、フォールト・トレラント状態の準備、シンドローム抽出、最終測定を実行するために、2 つの補助量子ビットが追加され、総計8 量子ビットが使用される。固有値 + 1 に関連付けられた2 つのスタビライザーの同時固有状態が、4 量子ビット論理空間を定義する。
スタビライザー測定時に -1を読み取ると、スタビライザーと互換性のないエラーが通知されるため、そのような回路の実行は破棄される。すべての論理ユニタリー演算が実行された後、2つのスタビライザーの測定値が+1であることを確認する最終測定を行い、論理パウリ期待値を読み取る。
クオンティニュアム は、「該社の忠実度の高いゲート操作(ゲート非忠実度〜 2 × 10−3)と全結合接続を組み合わせることで、論理エラー率が低い論理回路の実行が期待される」と主張する。さらに、該社のデバイスには、「条件付き終了機能が装備されており、シンドローム測定でエラーが検出されるとすぐに計算を破棄して、実行時間を節約できる」と主張する。
【4】実験セットアップと結果
水素間の距離RHH0.73486 Å の水素分子を対象としている。
(1) ハードウェアとソフトウェア
ハードウェアは、該社のH1-1(20量子ビット)を使用。
量子回路は、該社のコンパイラtketのpythonパッケージ「pytket(v1.13.2)」で準備され、pytket-quantinuum v0.15.0 で実行された。pytket-quantinuumは、pytketで作成された量子回路を該社のデバイスで実行できるように拡張されたpytketである。
量子化学計算は、該社の量子計算化学ソフトウェアプラットフォームである「InQuanto(v2.1.1)」とその pyscf v2.2.0へのインターフェイスを使用した。古典コンピューターで、スピンハミルトニアンの係数を計算する。pyscfは、pythonベースのオープンソース計算化学パッケージである。
パラメータ選択とベイズ推論のための古典的前処理と後処理は、phayes v0.0.3によって処理される。phayesはQPEを実行するpythonパッケージである。
(2) ハイパーパラメータなど
量子位相推定法(QPE)では、次のような重要な仮定を置く:試行関数が真の固有状態と、はじめから、ある程度の重なりを持っている(この重なりが小さければ、指数加速は達成されない)。これは、B-QPEでも同じ。この呪い(各種バージョンQPEの適用範囲を抑制するという意味)は、(言わずもがなであるが)意外と大きいように思われる。本論文では、QPE の入力状態(試行関数)として、計算化学で一般的に使用されるハートリー-フォック(HF)状態を用意する。本論文の場合、HF状態と真の基底状態との間の忠実度は 、0.981 である。
事後分布をフーリエ分布からフォン・ミーゼス分布に切り替える基準となるフーリエ係数の数2000 に設定され、量子回路の最大深さは120で指定される。脱分極エラー率p2は1.6 × 10−3 を使用する。なお、予想される廃棄率は77%(!)である。廃棄率とは、実行された回路の総数に対する廃棄された回路の数の比率である。
(3) 結果
ノイズを考慮した尤度関数を使ったB-QPEで計算されたエネルギーは、事後分布を125 回更新した後、−1.185 ± 0.009ハートリー(Ha)になった。一方、QEDを付けたB-QPEで計算されたエネルギーは、44 回の事後分布更新後に、−1.131 ± 0.007Haになった。正確な(基底状態の)エネルギーは、−1.1375Haである。つまり【1】の表記を使えば、1⃣+2⃣+3⃣よりも、1⃣+2⃣+4⃣の精度が高く、かつ計算量も少ない、という結果となった。
該社は、尤度関数にノイズを考慮するよりも、QEDの方が優れている、という結果を示したかったのだろう。
【5】感想
(1) かつてはFTQCが必須と言われたQPEも様々な工夫が凝らされ、NISQで実行できるようになったとアピールした論文である。本論文では、QPE自体の工夫に加えて、量子誤り検出符号による量子誤り抑制が大きく貢献している。廃棄率77%という数字自体も驚きであるが、それでもワークするということに、もっと驚いた。
(2) 100量子ビットオーダーのNISQマシンを使って、B-QPEにIBM激推しの誤り緩和(ZNEやPEC)を適用したら、どの分子サイズまで量子化学計算が可能なのか・・・と興味を持った。
【尾註】
*1 Pranav Chandarana et al.、Digitized-Counterdiabatic Quantum Algorithm for Protein Folding、https://arxiv.org/pdf/2212.13511.pdf
*2 鳩村拓矢・高橋和孝、断熱ショートカットとダイナミクスの構造、日本物理学会誌Vol.1,No.1,2021、pp.1-9、http://www.brl.ntt.co.jp/people/hatomura.takuya/STAreview_Butsuri_author_ver.pdf
*3 アミロイドβタンパク質は、KLVFF(Lys-Leu-Val-Phe-Phe)という特徴的なアミノ酸配列を持つ。KLVFF由来の小ペプチドKLVFFAは、アミロイドβ阻害活性をもつ。
*4 Bao Yan et al.、Factoring integers with sublinear resources on a superconducting quantum processor、https://arxiv.org/pdf/2212.12372.pdf
*5 https://www.schneier.com/blog/archives/2023/01/breaking-rsa-with-a-quantum-computer.html
*6 https://scottaaronson.blog/?p=6957
*7 柏原賢二、格子の最短ベクトル問題に対する離散的考察と並列計算アルゴリズム、https://jxiv.jst.go.jp/index.php/jxiv/preprint/view/60
*8 Craig Gidney,Martin Eker˚a、How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits https://arxiv.org/pdf/1905.09749.pdf
この論文(2021年4月)で、2000万物理量子ビットにまで、下がった(必要日数は0.31日≒7時間半)。2009年の論文では、65億物理量子ビットが必要と推定されていた(必要日数は410日)。物理ゲートの想定エラー率は0.1%。
*9 https://www.entropicalabs.com/post/implementing-real-world-optimisation-use-cases-in-state-of-the-art-quantum-devices
*10 https://www.nature.com/articles/d41586-023-00017-0
*11 Nikita Gourianov et al.、A Quantum Inspired Approach to Exploit Turbulence Structures https://arxiv.org/pdf/2106.05782.pdf
*12 固有直交分解については、例えば、平邦彦、固有直交分解による流体解析:1.基礎、ながれ30(2011)、pp.115-123(https://www.nagare.or.jp/download/noauth.html?d=30-2rensai2.pdf&dir=54)。テンソルネットワークに関しては、例えば、西野・大久保、テンソルネットワーク形式の進展と応用、日本物理学会誌 Vol. 72, No. 10, 2017、pp.702-711(https://www.jstage.jst.go.jp/article/butsuri/72/10/72_702/_pdf)
*13 米国のAI創薬スタートアップ、インシリコ・メディシンは、アルファ・フォールドを使って、肝細胞がんを対象とする新規ヒット化合物を発見した(Chemical Scienceに投稿した論文(https://pubs.rsc.org/en/Content/ArticleLanding/2023/SC/D2SC05709C)が23年1月10日に公開)。ターゲット選定から30日、7つの化合物を合成しただけで達成された。インシリコ・メディシンは、既にAIを使って発見した「特発性肺線維症」治療薬を開発している(フェーズ1が22年で終了、23年にフェーズ2aを開始)。なお該社は、22年6月には、シリーズDでUS$60milを調達。仏サノフィと最大12億ドル相当の戦略的研究提携契約を締結(22年11月)。
*14 NVIDIAとバイオスタートアップEvozyneは、AIを使って2種類のタンパク質を設計したと発表した(23年1月12日)。トランスフォーマーと変分オートエンコーダを組み合わせた。トランスフォーマーは、アルファ・フォールド2(AF2)及び(メタの)ESMフォールドでも使用されている。AF2は、多重配列解析(MSA)を行っているため、精度は高い半面、計算が遅い。ESMはMSAを行っていないので、速いが精度は低い。
*15 https://pr.fujitsu.com/jp/news/2023/01/23.html
*16 https://pressroom.credit-agricole.com/news/quantum-computing-two-real-world-experiments-conducted-by-credit-agricole-cib-in-partnership-with-pasqal-and-multiverse-computing-produce-conclusive-results-in-finance-cddc-94727.html
*17 Lucas Leclerc et al.、Financial Risk Management on a Neutral Atom Quantum Processor https://arxiv.org/pdf/2212.03223.pdf
*18 Harrison Mateika et al.、Fallen Angel Bonds Investment and Bankruptcy Predictions
Using Manual Models and Automated Machine Learning https://arxiv.org/ftp/arxiv/papers/2212/2212.03454.pdf
*19 (最新の)シミュレーテッド・アニーリング法を、200000回繰り返して得られた結果を正解として、ギャップ=|(損失関数(近似解)-損失関数(正解))/損失関数(正解)|、で計算する。
*20 Quantum computing:An emerging ecosystem and industry use cases(December 2021)
https://www.mckinsey.com/~/media/mckinsey/business%20functions/mckinsey%20digital/our%20insights/quantum%20computing%20use%20cases%20are%20getting%20real%20what%20you%20need%20to%20know/quantum-computing-an-emerging-ecosystem.pdf
*21 Raj G. Patel et al.、QUANTUM-INSPIRED TENSOR NEURAL NETWORKS FOR
PARTIAL DIFFERENTIAL EQUATIONS https://arxiv.org/pdf/2208.02235.pdf
*22 Raj G. Patel et al.、QUANTUM-INSPIRED TENSOR NEURAL NETWORKS
FOR OPTION PRICING https://arxiv.org/pdf/2212.14076.pdf
*23 PATRICK CHERIDITO et al.、Second-Order Backward Stochastic Differential Equations
and Fully Nonlinear Parabolic PDEs https://research.sabanciuniv.edu/id/eprint/7102/1/soner2.pdf
*24 ジェネレータに、正式な(?)日本語訳は、ないようである。
*25 斎藤祐一、金融規制の複合的影響を考慮したXVA、金融研究/2017.4、https://www.imes.boj.or.jp/research/papers/japanese/kk36-2-3.pdf
*26 El Amine Cherrat et al.、Quantum Vision Transformers https://arxiv.org/pdf/2209.08167.pdf
*27 OrganAMNIST、OrganCMNIST、OrganSMNISTのAはaxial、Cはcoronal、Sはsagittalを意味している。axialは、体軸面で切った画像という意味である。体軸面とは、(生物によって異なるが、ヒトの場合は)上側と下側に分割する面である。coronalは、冠状面で切った画像という意味である。冠状面とは、生物の体を腹側と背側(ヒトの場合は前側と後側)に分割する面である。sagittalは、矢状面で切った画像という意味である。矢状面とは、左右相称な動物の体の正中に対し平行に、体を左側と右側に分割する面である。
*28 El Amine Cherrat et al.、QUANTUM DEEP HEDGING、https://arxiv.org/pdf/2303.16585.pdf
*29 エテム・アルペイディン(久村典子 訳)、MITエッセンシャル・ナレッジ・シリーズ 機械学習 新たな人工知能、日本評論社、2017、p.144
*30 全ての量子ニューラルネットワークで、不毛な台地や勾配消失が発生するということではない。例えば、量子畳み込みニューラルネットワークでは、不毛な台地は発生しないようである。例えば(修士論文であるが)、大久保龍之介、変分量子アルゴリズムの応用と限界、https://www.icepp.s.u-tokyo.ac.jp/download/master/m2021_okubo.pdf
*31 例えば、以下があげられる:今木 翔太他、効率的な Deep Hedging のためのニューラルネットワーク構造、https://sigfin.org/?plugin=attach&refer=026-15&openfile=15_SIG-FIN-26.pdf
ちなみに、今木氏は理論物理専攻の院生で、プリファードネットワークスのインターンシップに参加した際に、研究を行い、論文作成したそうである。また、この論文は、人工知能学会の研究会優秀賞を受賞している(https://tech.preferred.jp/ja/blog/deep-hedging/)。
*32 ヨーロピアン・オプションとルックバック・オプションを対象として、実証している。ちなみに、ルックバックを「経路依存性をもつ複雑なデリバティブ」と表現している(https://tech.preferred.jp/ja/blog/deep-hedging/)が、少なくともトレーダーには、複雑なデリバティブとは認識されていない。実際、原資産価格がブラックショールズ・モデルに従う場合、ルックバック・オプションは解析解を持つ。
*33 上田翼、強化学習を用いた期待効用ベースヘッジ手法、https://sigfin.org/?plugin=attach&refer=024-23&openfile=20_SIG-FIN-24.pdf
*34 正確には、ブラックモデルによるデルタヘッジの平均効用0.047に対して、強化学習によるディープヘッジの平均効用が0.048。主なセットアップは以下の通り:米国債券先物オプションを、原資産=米国債券先物でヘッジ。原資産はヘストンモデルに従うと仮定。原資産価格=100+ε、行使価格=100、ストラテジーはショートストラドル。満期T=40まで保有して終了。期限前行使なし、満期にITMの場合は、原資産に転換される(とともに、ポジション解消に必要な売買を行う)。取引コストはヘッジ資産の売買量に比例すると仮定。
*35 篠崎裕司(日本銀行金融研究所経済ファイナンス研究課)、深層学習によるファイナンスの新展開 ディープ・ヘッジングの紹介、2022年11月11日、https://www.imes.boj.or.jp/jp/conference/finance/2022_slides/1111finws_slide3.pdf
*36 例えば、一般社団法人金融データ活用推進協会、金融AI成功パターン、日経BP、2023、p.223
*37 Po-Yu Kao et al.、Exploring the Advantages of Quantum Generative Adversarial Networks in Generative Chemistry、https://pubs.acs.org/doi/pdf/10.1021/acs.jcim.3c00562
補足情報は、以下の論文にある。https://pubs.acs.org/doi/suppl/10.1021/acs.jcim.3c00562/suppl_file/ci3c00562_si_001.pdf
*38 Enterprise Quantum Computing Adoption、https://www.zapatacomputing.com/enterprise-quantum-adoption-2022/
*39 ザパタ自身も量子版生成モデルを使って、成果を出している(と主張している)。BMWのプラントスケジュール最適化問題に、量子生成モデルあるいは量子インスパイアード生成モデルを適用し、汎化性能をあげた、とする(https://zapata.wpenginepowered.com/wp-content/uploads/2023/04/Generator_Enhanced_Optimization.pdf)。
*40 Nicola De Cao and Thomas Kipf、MolGAN: An implicit generative model for small molecular graphs、https://arxiv.org/pdf/1805.11973.pdf
ちなみに、大分子に拡張したL-MolGANというモデルもあるらしい。https://chemrxiv.org/engage/chemrxiv/article-details/60c75942ee301c4f75c7b892
*41 米qBraidは、量子ソフトウェア・スタートアップで、量子ソフトウェアを開発するための、クラウド・プラットフォームを提供している。
*42 Henry Makhanov et al.、Quantum Computing Applications for Flight Trajectory Optimization、https://arxiv.org/pdf/2304.14445.pdf
*43 例えば、大関真之(監訳)、量子コンピュータによる機械学習、共立出版、2020、p.135、脚注11。
*44 例えば、量子敵対的生成モデル(QGAN)では、学習率を上げることができるため、(学習の)エポック数を減らすことができる。つまり、学習を短縮できる。古典GANでは、学習率を上げるとモデルは非常に不安定になり、うまく学習できない、と言われている。
*45 Jonas Stein et al.、Quantum Surrogate Modeling for Chemical and Pharmaceutical Development、https://arxiv.org/pdf/2306.05042v1.pdf
*46 これには、あまりに表層的という批判があるかもしれない。材料開発等の現場における生データは複雑すぎて、そのままでは使えない(から結果的にデータが少ない)、という指摘もある。
*47 Sukin Sim et al.、Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum-classical algorithms、https://arxiv.org/pdf/1905.10876.pdf
*48 例えば、一般社団法人金融データ活用推進協会、金融AI成功パターン、日経BP、2023、pp.63-66
*49 ibid.、pp.138-139
*50 科学技術振興機構 研究開発戦略センター、研究開発の俯瞰報告書|ライフサイエンス・臨床医学分野(2023)、https://www.jst.go.jp/crds/pdf/2022/FR/CRDS-FY2022-FR-06/CRDS-FY2022-FR-06_20103.pdf
*51 Lucas Friedrich and Jonas Maziero、Quantum neural network cost function concentration dependency on the parametrization expressivity、https://www.nature.com/articles/s41598-023-37003-5
*52 例:転移学習を用いて、金属の破面分類高精度化を行った研究がある。上杉徳照他、材料の種類を考慮した転移学習による破面分類(https://www.jstage.jst.go.jp/article/jsms/72/5/72_376/_pdf/-char/ja) ステップワイズ元クラス選択法を用いている。
対象金属は、合金鋼、オーステナイト鋼、銅・銅合金の3種類。学習モデルはCNN(正確にはVGG16)で、Kerasにて実装。活性化関数としてReLUを使用。過学習対策として、ドロップアウト、バッチ正規化、Early stopping(最大エポック数100)を採用。損失関数は、交差エントロピー誤差。オプティマイザーはAdam。学習時間1.5時間。
正解率は、6.3%ポイント(92.4%→98.7%)上昇した。ちなみに、合金鋼と銅・銅合金の正解率は100%で、オーステナイト鋼だけ96%と低かった。
*53 Kentaro Yamamoto et al.、Demonstrating Bayesian Quantum Phase Estimation with Quantum Error Detection、https://arxiv.org/pdf/2306.16608.pdf
*54 量子化学、論理量子ビットを用いて誤り耐性の領域へと大きく前進、https://quantinuum.co.jp/n20280710/
*55 杉﨑研司、FTQCアルゴリズムを用いた分子の高精度量子化学計算に向けて、https://qsw.phys.s.u-tokyo.ac.jp/assets/files/20211207_sugisaki.pdf
*56 大西裕也、特集[面白いぞ量子技術]5 量子コンピュータと量子化学計算―量子コンピュータによって量子化学は恩恵を受けるのか?―、情報処理 Vol.62 No.4 (Apr. 2021)、pp.28-34、
https://koara.lib.keio.ac.jp/xoonips/modules/xoonips/download.php/KO50002002-20215739-0003.pdf?file_id=163263
*57 N. Wiebe & C. Granade、Efficient Bayesian phase estimation、https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.117.010503
*58 例えば、https://kaken.nii.ac.jp/ja/file/KAKENHI-PROJECT-17K00358/17K00358seika.pdf
*59 Chris N. Self et al.、Protecting Expressive Circuits with a Quantum Error Detection Code、https://arxiv.org/pdf/2211.06703.pdf
*60 例えば、以下:石垣克明、|日本銀行金融研究所ディスカッション・ペーパー| 量子計算の概要:ファイナンスへの応用を例に、2023年8月、https://www.imes.boj.or.jp/research/papers/japanese/23-J-10.pdf、p.51
*61 日本のアステラス製薬も参加している。出典:https://www.jstage.jst.go.jp/article/toxpt/48.1/0/48.1_S12-3/_pdf/-char/ja
*62 2022年のIPCC報告書では、飛行機雲は航空による地球温暖化の影響のおよそ35%を占めており、これは世界のジェット燃料の影響の半分以上であると指摘されている。Google、アメリカン航空他は、AIを使って飛行機雲発生予測マップを作成し、パイロットが飛行機雲の発生を避けるルートを選択できるかどうかをテストした。その結果、飛行機雲の発生を54%減らすことができた。
出典:https://atmarkit.itmedia.co.jp/ait/articles/2312/13/news072.html#utm_medium=email&utm_source=tt_news&utm_campaign=2023/12/14
*Supp-2 Nikhil Khatri et al.、Quixer: A Quantum Transformer Model、https://arxiv.org/pdf/2406.04305